Datasjø – derfor byr det på et hav av muligheter
Brukt riktig vil en datasjø kunne gi enorm innsikt i virksomheten, samt optimalisering og effektivisering av ulike tjenester og prosesser.

I vår organisasjon er det få som vet så mye om datasjøer som Pål A. Reiersgaard. Pål jobber som Tech Lead i Lungegårdsvannet, som er navnet på datasjøprosjektet i Bergen kommune, og er lidenskapelig opptatt av behandling og analyse av store datamengder. Han er klokkeklar på at datasjøer er fremtiden og at mulighetene det skaper ikke bare vil være nyttige for store selskap som Equinor, men at det vil være minst like nyttig for kommunale aktører som Bergen kommune.
– Om du skaffer innsikt i egne data og tilrettelegger dem på en fornuftig måte, vil det kunne gi enorme gevinster for virksomheten. Demokratisering av data og strukturering av store datamengder legger også til rette for maskinlæring, prediktiv analyse og utvikling av autonome prosesser. Alt dette har Bergen kommune forstått, og for litt over ett år siden satte de i gang sitt eget datasjøprosjekt. Nå, ett år etter, kan vi slå fast det har vært en stor suksess som også byr på store muligheter for fremtiden, forteller Pål Asle.
Her kan du lese om resultatene vi har fått i vårt prosjekt med Bergen Kommune!
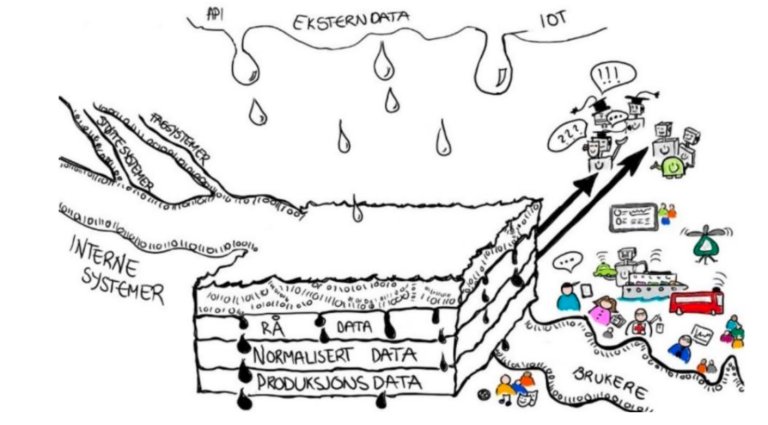
Men aller først for deg som ikke vet det allerede: Hva er en datasjø?
– Kort fortalt handler det hele om å samle inn en haug med informasjon, gjerne i skyen, og deretter gjøre noe lurt med disse dataene. Med data i en sjø mener vi alt mulig; strukturerte data, ustrukturerte data, bilder, tekst, filmer, osv. Ved å for eksempel samle inn sensordata på mikrosekund- eller minuttnivå, kan du generere et veldig stort datagrunnlag. Brukt riktig kan dette bidra til en bedre forståelse av det underliggende bak ulike prosesser. En datasjø vil også gjøre det mulig å tilgjengeliggjøre dataene på en slik måte at det i større grad kan tilrettelegges for innovasjon, analyse, deling av data, samt tilgjengeliggjøring av åpne og sensitive data for de som skulle ha behov for disse, forklarer Pål Asle.
Ifølge Pål er det likevel ikke slik at det bare er å samle masse data i en datasjø, for så å slå på maskinlæring, slik at data kan fortelle hva du skal gjøre. Han påpeker at 80 prosent av jobben er å bygge opp et godt fundament, ved å trekke ut data på en sikker og god måte og deretter prosessere og behandle dem med omhu. Alt dette bør hele tiden gjøres sammen med forretningen, slik at du gjør de riktige tingene rett. Du må ha en plan for hva du ønsker at dataene skal brukes til, og nettopp dette er det heldigvis nå flere som forstår.

Selvbetjening og analyse med Power BI
Hvilke utfordringer kan løses med en datasjø?
Først og fremst handler det i følge Pål Asle om knekking av siloer. Ved å samle data fra ulike fagområder og sektorer, ta det rått inn i datasjøen, og å sette dem i en sammenheng, kan en datasjø løse både store og små utfordringer. Det å kunne se data på tvers av siloer gir også ofte gevinst med én gang, da du enklere kan se sammenhenger mellom din egen kjernevirksomhet og fagområder som for eksempel regnskap og HR.
– Det handler mye om at du i mye større grad får tilgjengelighet og skalerbarhet i skyen/sjøen. Det er ofte skepsis rundt det å flytte data opp i skyen, men grunnet alle fordelene som følger, merker vi nå at flere mykner opp for å starte skyreisen. Med en datasjø bygget på en sky-tjeneste, kan du nemlig redusere eller kvitte deg helt med den fysiske maskinparken. Istedenfor kan du kjøre alt opp i skyen, enten det er Azure, AWS eller andre plattformer. Det å ha tilgang til ressursene i skyen, og det å kunne oppskalere og nedskalere etter behov, er en utrolig stor fordel, forklarer Pål Asle.
Et annet av grunnprinsippene for datasjøen er deling og åpenhet. De ulike skytjenestene gjør at vi relativt enkelt kan få dette til. I datasjøen lagrer vi data «rått» og prøver å legge til rette for deling av data. Ikke-sensitive data, som for eksempel badetemperaturer, kan enkelt deles ved at vi utvikler et enkelt API.
– Bare det å kunne visualisere ulike data for «de på gulvet» åpner for muligheter vi kanskje ikke har hatt tidligere. Selv har jeg lang erfaring fra helsesektoren, og bare det å kunne trekke ut uforståelige data fra fagsystemet til for eksempel legevakten inn i datasjøen og tilgjengeliggjøre det på en strukturert måte, vil gi svært verdifull og omtrent umiddelbar innsikt, påpeker Pål Asle.
På sikt, fordi man har så mye kraft i skyen, vil man gjennom å kjøre prediktiv analyse og maskinlæring på dataene, etterhvert også kunne bruke dataene til å skape autonome prosesser, som for eksempel å bruke dataene til å skru av og på en bryter basert på andre hendelser, eller å programmere selvkjørende biler. Mulighetene er rett og slett enorme!
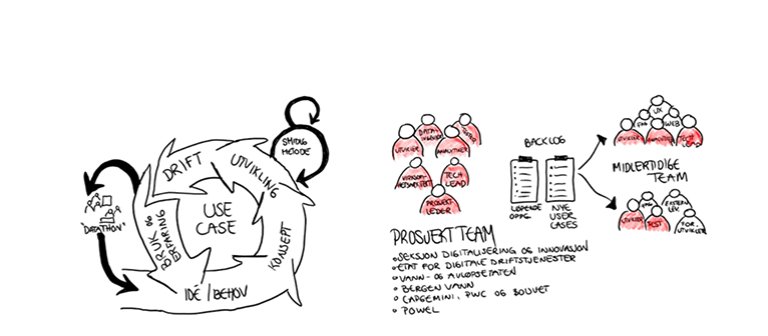
Slik lykkes du med et datasjøprosjekt
Skal du sette i gang med dit eget datasjøprosjekt, har Pål noen pointers.
- Først og fremst må jeg understreke at 80% av jobben ligger i å bygge det som er under panseret. Er du flink til å bygge en god grunnmur med hensyn til dokumentasjon, datakvalitet og ivaretagelse av personvern, er det ingen begrensninger for hva du kan bruke data til.
- Samtidig er det også essensielt å ha forankring i toppledelsen. De på toppen må ha en viss forståelse for hva og hvorfor. Du må også ha riktig personell og et godt sammensatt team både administrativt og teknisk. Å koble forretningen sammen med utviklingen er Alfa og Omega. På denne måten sikrer du at du utvikler noe forretningen faktisk trenger og har behov for.
- Du må tørre å satse litt, og forstå at det koster. Å flytte ting over til skytjenester kan ofte føre til at det dere bruker på lagring og prosessering av data blir mer synlig, fordi dere betaler ut i fra hvor mye dere bruker skytjenesten. Lagrer du «on premise», er dette ofte bakt inn i andre budsjetter. Den alternative kostnaden ved å ikke flytte over til skyen, kan dog bli veldig stor, fordi de store aktørene nå flytter hovedvekten av all utvikling over i skyen, samt at det loves 99% «oppetid», som gjør det mye sikrere å lagre data der.
- Maskinlæring og avansert analyse av dataene kan se veldig kostbart ut, men det ikke alle tenker på er at du kan kjøre veldig tunge analyser med store mengder data i ett døgn, for så å slå det av og se på resultatet. Du trenger ikke kjøre dette kontinuerlig.
- Du må ha en plan! Her må jeg bruke anledningen til å skryte litt ekstra av Bergen kommune. De har nemlig hatt en «use case-tilnærming» fra start. Det betyr at de har tatt utgangspunkt i en ganske omfattende brukerhistorie som skal danne grunnlag for et konsept. Å gjøre det på denne måten fører til at kundene på forhånd må argumentere og vise hva de skal bruke dataen til. Når vi som fageksperter kan gjøre dette sammen med kunden på denne måten, oppnår vi en trygghet i at det vi lager har en nytteverdi, og det har vært en av de virkelig store suksesskriteriene for vårt datasjøprosjekt.