Hvordan komme i gang med Reinforcement Learning
Denne artikkelen vil ta for seg litt om hva RL er, hva slags biblioteker og rammeverk som er tilgjengelig og hvordan man kan komme i gang med å trene en enkel RL agent.

Motivasjon
Reinforcement Learning (RL) har fått mye oppmerksomhet i det siste på grunn av Google Deepmind. De lagde en algoritme i 2015 som oppnådde «superhuman performance» i mange Atari 2600 spill og senere kunne spille «First-person shooter» (FPS) spill som Doom.
Deepmind lagde senere en algorithme (AlphaGo), som lærte seg selv å spille brettspillet Go og i mars 2016 slo verdensmesteren Lee Sedol. Denne algorithme ble generalisert til AlphaZero og er nå verdensmester i sjakk, shogi og Go. En viktig detalj er at algoritmene i mange tilfeller bare får et bilde som input (brettet eller spill-skjermen) i tillegg til poengsummen, og lærer seg en oppførsel i spill miljøet, som gir mest poeng, uten annen informasjon. Noen eksempler kan ses i Figur 1.

I det siste året så har biblioteker blitt laget for å kunne anvende RL i industrien. Og RL er ikke bare for spill, den har så vidt begynt å få sine anvendelser som gir verdi til bedrifter. Et eksempel på dette er hvordan RL minsket kjølingsregningen for datasenteret i Google med 40%. Det vil sannsynligvis komme mange anvendelser for RL i nærmeste fremtid.
Denne artikkelen vil ta for seg litt om hva RL er, hva slags biblioteker og rammeverk som er tilgjengelig og hvordan man kan komme i gang med å trene en enkel RL agent, ved å bruke et nytt rammeverk som kalles «RLlib: Scalable Reinforcement Learning». Man vil lære å:
- Bruke «Tensorboard» for å overse treningen.
- Trene en agent med RLlib og et OpenAI gym miljø.
- Kjøre av ferdig trent agent modell.
Det som trengs er Linux (Windows subsystem skal også fungerer) og Python. Trenger også Python pakkene Ray 5.0 med RLlib, Tensorflow og OpenAI gym installert.
Hva er RL
Målet for RL er at en agent skal lære seg å maksimere total forventet belønning eller poengsum. Det vil si at selv om miljøet er stokastisk så vil agenten fremdeles lære oppførselen som har størst sannsynlighet for å gi den maksimale belønningen, og at det er den totale slutt poengsummen som er viktig, ikke bare midlertidige belønninger.
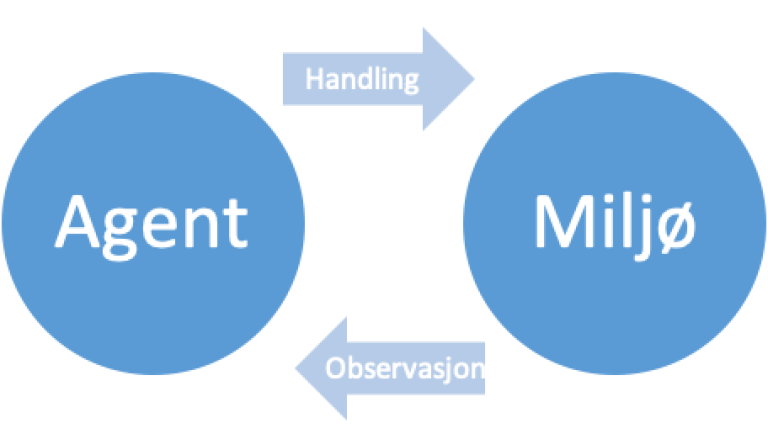
RL kan beskrives slik som diagrammet i Figur 2, det består av to deler, miljø (Environment) og agent. Agenten genererer handlinger og miljø skal generere observasjoner og belønninger.
Bibliotek for miljøer
Miljøer er simuleringer eller spill som Agenten kan trene på. Dette kan brukes til å sammenligne algoritmer, lære om RL og for videre forskning. I denne artikkelen vil vi fokusere på et OpenAI miljø. Hvis man skal anvende RL så må man lage miljøet selv. For eksempel en «digital twin» eller en simulering. Eventuelt kan det være reelle signal data fra virkeligheten, men merk at det kreves ekstreme mengder med data for å trene en RL agent. Eksempler på noen miljøbiblioteker kan ses i Tabell 1.
| Bibliotek | Kommentarer |
| OpenAI Universe | Et API for å integrere de fleste spill som et miljø |
| OpenAI Gym | Innholdet mange forskjellige miljøer, eksempel klassiske kontroll problemer som balanse, og Atari 2600 spillene |
| DeepMind Lab | Et FPS miljø, som bruker Quake motoren, eksempel labyrinter i første persons perspektiv. |
| DeepMind Control Suite | MuJoCo physics engine problemer |
| Project Malmo | Minecraft miljø, Microsoft Research |
| VizDoom | Miljø for Doom (1993), har konkurranser der blant annet Facebook og Intel har verdt med |
| ALE | Atari 2600 |
| Gym Retro | Veldig mange gamle spill, Atari, Sega. osv |
| Unity | Miljøer med Unity motoren |
| Comm AI
|
Fra Facebook |
Tabell 1: RL miljøer
CartPole miljø
CartPole er en populære "miljø" i OpenAI for reinforcement learning. Hensikten er å flytte "cart" fram og tilbake for å kunne holde "pole" balansert. Figur 3 viser hvordan dette fungere.
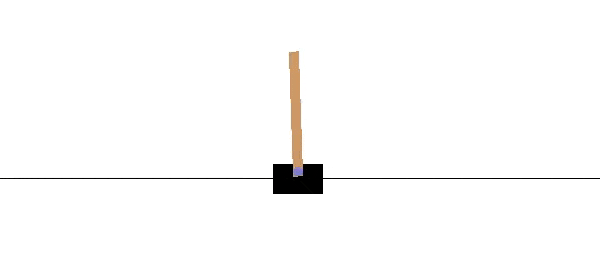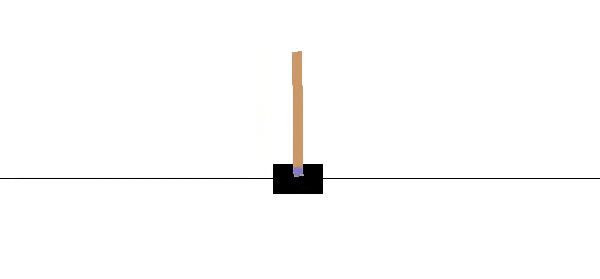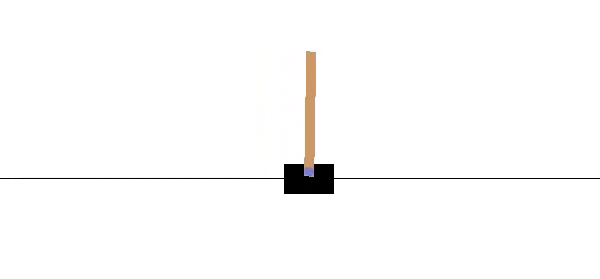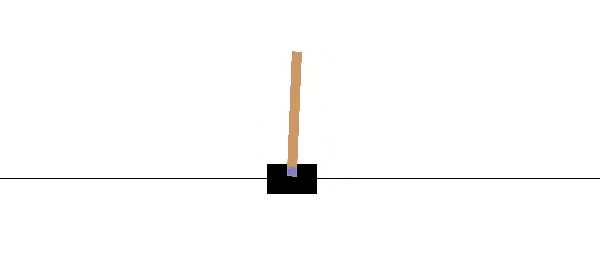
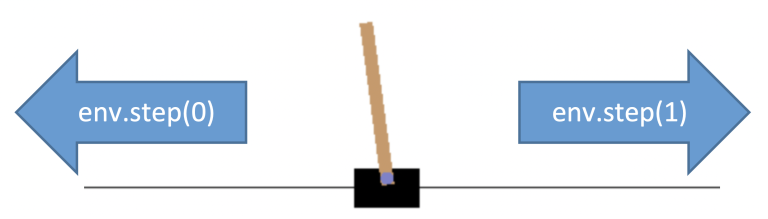
I figur 4 ser vi en "treningsmilø" for CartPole. Pilene viser at man kan ta handlinger et steg venstre eller et steg høyre.
Observasjonene fra dette miljøet kan se slik ut:
[-0.10451683 -0.57487873 0.16187209 1.11000294]
Dette er hhv: CART POSITION, CART VELOCITY, POLE ANGLE, POLE VELOCITY AT TIP.
For å teste CartPole-V0 miljøet så kan man kjøre miljøet med noen tilfeldige handlinger.
import gymenv = gym.make("CartPole-V0")observation = env.reset()
for _ in range(1000):env.render()
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
env er miljøet, viktigste funksjonene til miljøet er step() og reset().
- reset() resetter miljøet til start tilstanden.
- step() utfører en handling i miljøet.
Når en handling blir utført med step, så returnere den en tuppel med fire variabler, dette er:
- Observasjonen: Observasjonen av neste tilstand.
- Belønningen: en skalarverdi av belønningen for akkurat dette steget.
- Done: En boolsk variabel som er True viss miljøet har kommet til en slutt tilstand, da er episoden ferdig og spillet må starte på nytt (reset).
- Info: En Dictionary som kan innholde debuginfo eller annet.
Man kan også printe ut disse variablene for å se hva de inneholder. Eksempel CartPole-V0 observasjonene er vektorer med fire flyttall, dette kan ses i Figur 4. Merk at Observasjonen til miljøet er det som Agenten må forholde seg til å basere sine handlinger på.
Belønningene er 1.0 for hvert steg. d.v.s jo lengre man balanserer, jo mer poeng. Viss CartPole får for stor vinkel så har man kommet til slutt tilstanden og episoden slutter.
RL algoritmene må bruke dette API’et for å trene.
Rammeverk for trening av Agenter
For ett år siden var det ikke mange tilgjengelige RL implementasjoner, men i dag så finnes det nå en rekke valgmuligheter. Det viktigste er at algoritmene er implementert korrekt, er fleksible til å modifiseres og kan kjøres effektivt på forskjellig hardware. For eksempel kan parallelliseres på 70 CPU instanser fra Amazon AWS. Denne listen vil nok vokse fort.
| Rammeverk/bibliotek | Kommentarer |
| RLlib | RL bibliotek som er effektivt og modulært og bygger på parallellise-rings rammeverk Ray, assosiert med UC Berkeley |
| OpenAI baselines | Startet av blant annet Elon Musk, er veldig nøyaktige implantasjoner av algoritmene, men er mindre fleksible og har hovedvekt på å kunne reproduseres forskningsresultater |
| Dopamine | Nytt RL bibliotek fra Google |
| Reinforcement Learning Coach | RL fra Intel, skal være optimalisert for Intel hardware |
| Garage | Pieter Abbeel fra UC Berkeley/OpenAI |
Tabell 2: Noen av RL treningsbibliotekene, som inneholder treningsalgorithme
Denne artikkelen vil fokusere på RLlib. RLlib har en aktivt Github, koden er laget for industrielt bruk, med bra utnyttelse av hardware. Den er modulbasert som gjør koden veldig fleksibel. Algoritmene er korrekt implementert og gir forventet resultater, som uttrykt i publikasjonene for algoritmene. Dopamine fra Google virker også veldig interessant men er helt nytt og har ikke blitt testet enda.
Trene en agent med RLlib
Neste steg er å la RLlib trene en Agent i CartPole-V0 miljøet, num_workers må være mindre eller likt antall CPU kjerner - 1 på maskinen som brukes.
Algoritmen som brukes er PPO (Proximal Policy Optimization) og det er mange hyper-paramtere som kan settes i config, for mer informasjon sjekk RLlib dokumentasjon og PPO publikasjonen.
import rayimport ray.tune as tune ray.init()tune.run_experiments({ "my_experiment":{ "checkpoint_freq":1, "run":"PPO", "env":"CartPole-v0", "config":{"num_workers":7} },})Oversikt over treningen mens Agenten trener
Start en ny konsoll, eller kjøre treningen i bakgrunnen:
- Naviger inn i «~/ray_results» mappen, som skal ha blitt laget
- Så kjør kommandoen «tensorboard --logdir=.»
- Man får da opp en URL, eksempel «localhost:6006»
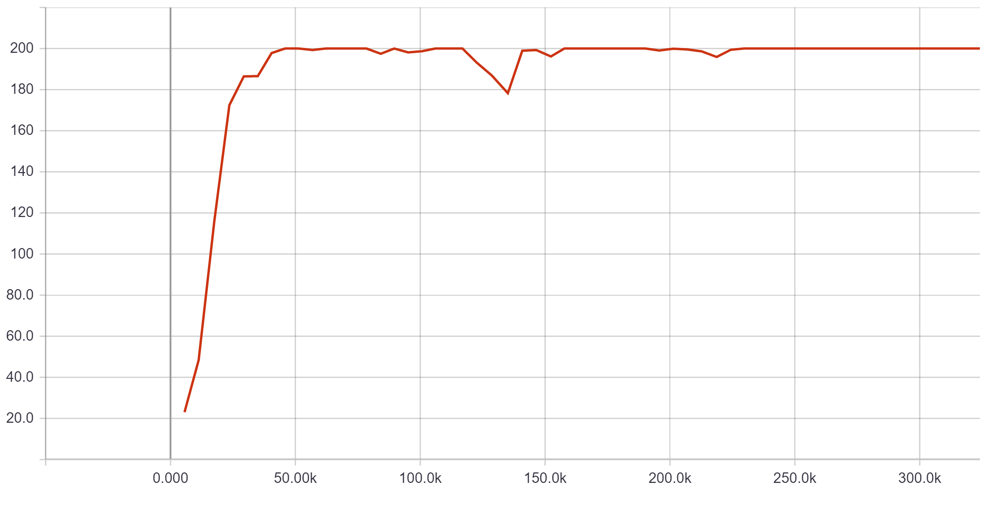
Denne skriver man inn i nettleseren. Her får man oversikt over treningen som foregår. Viktigste er plottet «ray/tune/episode_reward_mean», her ser man antall steg som RLlib har simulert i miljøet i x-aksen og gjennomsnittlig total belønningsoppnåelse i y-aksen. Forhåpentligvis så går denne grafen raskt oppover. Innen noen par minutter så skal den ha lært seg å balansere stangen, med maks total episode belønning på 200, se Figur 5 under.
Kjøring av Agent modell
De trente Agentene blir lagret i RLlib sitt eget format. Men det er mulig å konvertere dette til normal Tensorflow modell, som blant annet kan kjøre på windows viss det trengs. Neste steg er å bruke RLlib sin API for å hente agenten igjen. Det gjøres i koden under, velg den siste checkpoint filen, eventuelt nest siste. Eksperimentet har navnet «my_experiment» som ble definert tidligere.
import rayimport osimport gymfrom ray.rllib.agents.agent import get_agent_class ray.init()cls = get_agent_class("PPO")agent = cls(env = "CartPole-v0")checkpoint_path = os.path.expanduser('~/ray_results/my_experiment/PPO_CartPole-v0_0_2018-11-05_13-21-55nkbnts7y/checkpoint-8')agent.restore(checkpoint_path)Når agenten er lastet inn, så kan man kjøre igjennom en episode der man bruke agent.compute_action med observasjon som input. Og får ut handlingen som skal utføres. Dette går da inn i miljøets step funksjon. Med env.render() så kan man se visuelt hvordan agenten balanserer. Ellers vil den totale episode belønningen vise at den får makspoengsummen ~200 poeng.
env = gym.make("CartPole-v0")
obs = env.reset()
done = False
episode_reward = 0
while not done:
env.render() #kommenter denne ut hvis man er i windows subsystem
a = agent.compute_action(obs)
obs, r, done, info = env.step(a)
episode_reward += r
print(episode_reward)
Denne artikkelen gikk igjennom hvordan man trente en Agent for å løse et CartPole-V0 miljøet, Det ble brukt RLlib rammeverket for RL algoritmene. Under treningen ble agentens framgang overvåket med Tensorboard, og etter treningen ble modellfilen brukt til å vise hvordan agenten har lært seg å løse CartPole-V0 problemet.

