Smarten up your Pi Zero Web Camera with Image Analysis and Amazon Web Services (Part 1)

Update 06 Aug 2018: In case you are interested, I've just published a new blog about creating an AI powered security camera using the Raspberry Pi and Movidius Neural Compute Stick!
Introduction and Recap
In my previous blogpost I described how I built a simple security camera using a Raspberry Pi Zero and the Motion software package. The result sends me image snapshots via email when it senses motion in my back garden.

The Motion software works by comparing each frame of the incoming video stream. If the total amount of pixels is over a given threshold then a "motion detected" event is triggered. The Motion software does not care what it's looking at, only that the image has changed.
This algorithm resulted in a large amount of false positives being triggered by moving shadows, the neighbours cat and even raindrops running down the window past the camera lens. This was a problem as I received an email alert for each false positive (up to 50 a day) making my camera much like the boy who cried wolf. I therefore needed a solution to reduce these false positives and make my camera more trustworthy.
Initial Thoughts on addressing False Positives
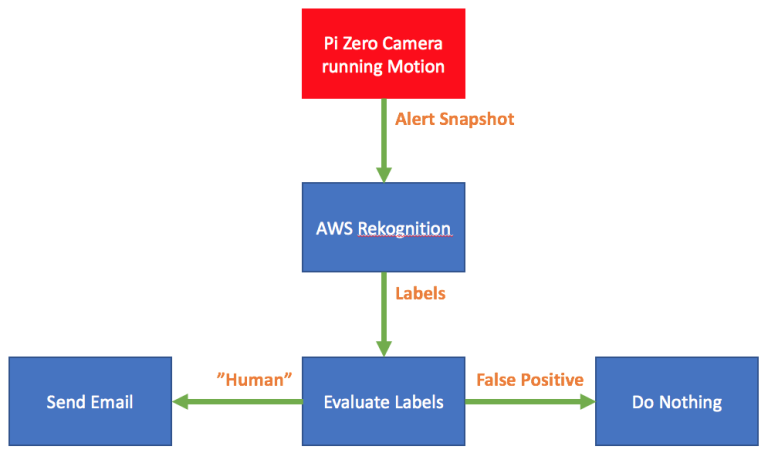
I realised that my security camera project needed a “filter” that would be able to look at the snapshots from Motion and distinguish between false positives and those containing people. This filter could then be used to reduce the amounts of email alerts I was receiving.
My first thought was to look into Open CV’s support for facial detection, but I quickly realised that this wouldn’t be of any use if the intruder(s) were all facing away from the camera!
I then played with the idea of using a machine learning solution such as TensorFlow to analyse the snapshot images and determine whether or not they contained a person. TensorFlow is certainly up to the job, but requires a significant time investment to get up to speed. As a father of two I just didn't have the available time to invest in understanding algorithms for machine learning.
I was also restricted by the Pi Zero's limited processing resources. Installing lots of additional software might adversely affect the performance of the Motion software.
Image Analysis as a Service
Early in December 2016 I was browsing my Twitter feed when I came across this:

For those of you who don’t know, re:Invent is a conference for customers of Amazon Web Services (also known as AWS). I’d never touched AWS before, but this Tweet piqued my interest. It turned out that Amazon had just launched a new IAaaS (Image Analysis as a Service) solution called AWS Rekognition that might help solve my false positive problem.
AWS Rekognition
Rekognition is built upon deep neural network models. It can detect and label thousands of objects and scenes in provided images, and Amazon are continually adding new labels and facial recognition features to the service.
I was most interested in the DetectLabels function, which returns a list of labels for a given image, along with a confidence score for each label.
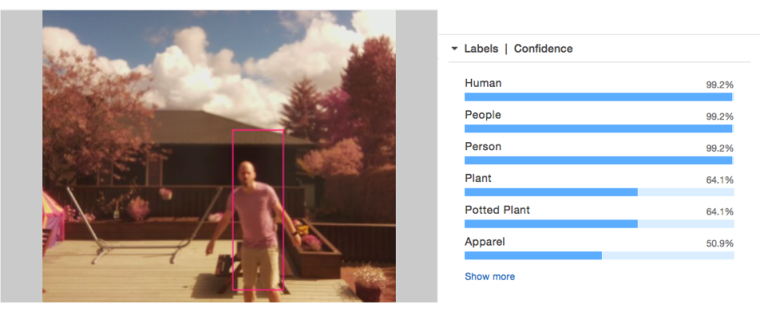
As you can see from the above example, Rekognition can be used to determine whether or not a person is in a given image. By adding DetectLabels to my Web Camera project I'd be able to remove all the false positives that I had been getting!
Cost wise, Rekognition is a reasonable option. Under the AWS Free Tier I am able to process 5,000 images per month, for up to 12 months. At which point the cost will rise to a whopping $1 per 1,000 images.
I also checked out two alternatives to Rekognition:
- Google Vision offers the same functionality as Rekognition. Frankly I found it's pricing model hard to understand (not that I tried to hard).
- Clarifai offers the same functionality as Rekognition and is completely free, as long as you keep the number of API calls under 5000 a month. Clarifai also allows you to improve the Image Analysis quality by using categories and training.
Both these options compared well to Rekognition, but performed worse on some of the test pictures that I supplied them with. However it is important that all three of these services are constantly under improvement which will mean the frontrunner may change at any given time.
After deciding to continue with Rekognition I needed to address the next question - how would I incorporate it into my existing solution?
To Be Continued....
Part two of this blog post is now up and contains:
