Ved å overvåke og balansere kraftnettet forhindrer Statnett at det blir overbelastning og strømbrudd, og du er sikret strøm fra stikkontakten din. Bouvet er en av Statnetts samarbeidspartnere i dette viktige arbeidet, og bistår med å utvikle, drifte og vedlikeholde flere prediktive maskinlæringsmodeller som skal sørge for at det stadig produseres og forbrukes like mengder strøm.
Statnett er ansvarlig for å bygge, drifte og vedlikeholde det norske kraftsystemet. De skal sikre strømforsyningen gjennom drift, overvåking og beredskap døgnet rundt og legge til rette for å realisere Norges klimamål, og for verdiskapning for våre kunder og samfunnet.
Enkelt forklart jobber vi med å utvikle et system som beregner ubalanse i strømnettet i sanntid, og lager en prognose for hvordan det vil utvikle seg. Prognosen bestemmer hvor mye strøm som skal kjøpes eller selges i balansemarkedet, og systemet utfører de nødvendige handlene, slik at vi oppnår balanse i strømnettet på rimeligst mulig måte.
Peter Sandberg, Bouvet. Data scientist, utvikler og løsningsarkitekt i prognoseprosjektetSlik brukes modellene
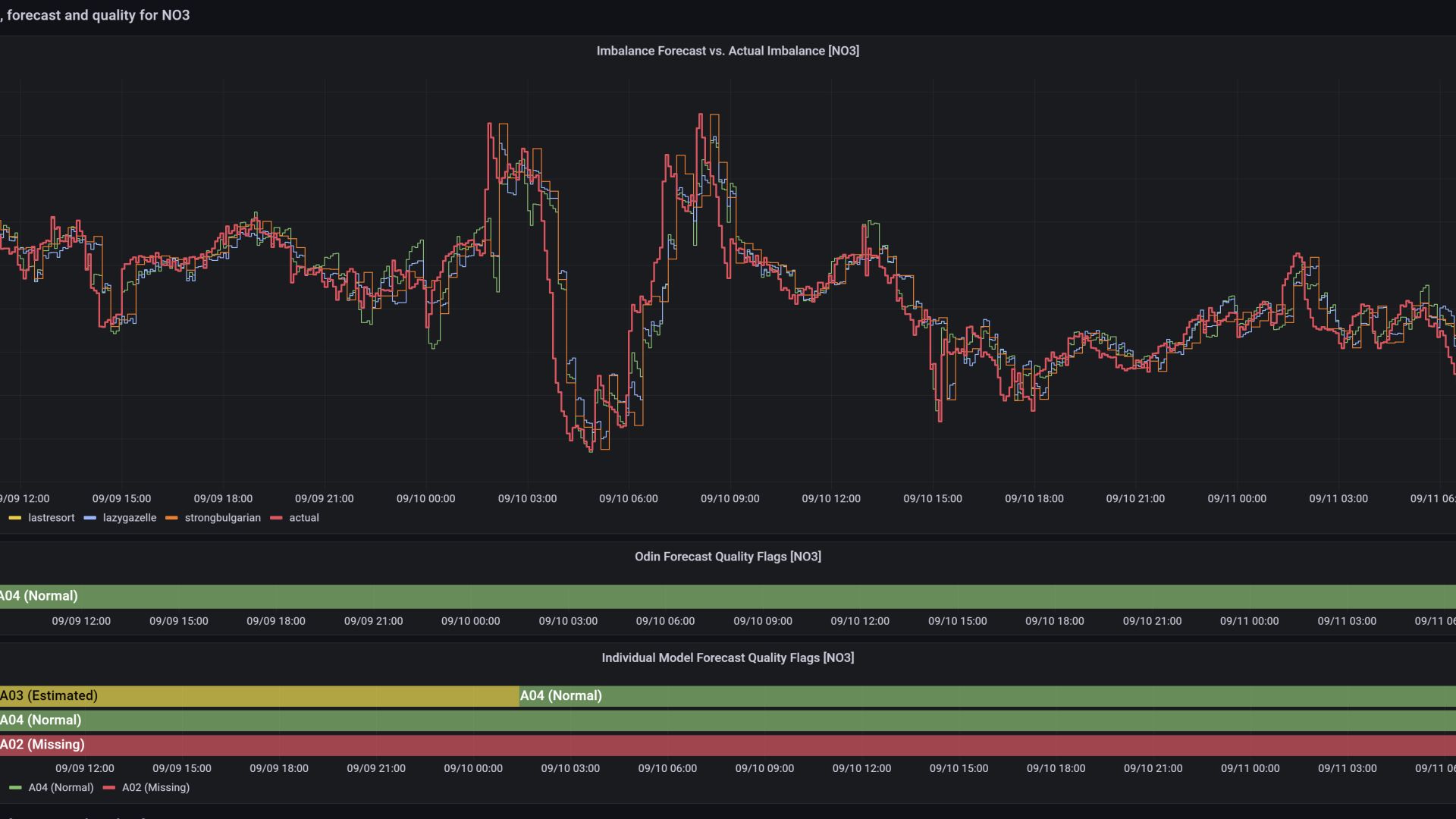
Maskinlæringsmodellene analyserer og predikerer ubalanse i strømnett, forventet strømforbruk, og strømproduksjon som kommer fra vindkraft. Hvis modellen sier at det er forventet at forbruk overstiger produksjon med 1000MW kommende kvarter, så må Statnett regulere opp 1000MW. Det kan de gjøre ved å betale noen for å skru opp produksjonen sin, eller betale noen for å skru ned forbruket sitt.
Flere modeller kjører samtidig, hver basert ulike inputkilder og algoritmer. Dette gir økt robusthet, fordi man automatisk kan bytte til en enklere modell når mer komplekse modeller feiler. Det gjør det også mulig å sammenligne hvilken modelleringsstrategi som funker best på live data - som ikke nødvendigvis ser lik ut som historisk data brukt under trening. I tillegg er det blitt utviklet en sett med automatiserte prosesser og rammeverk for å bygge og deploye maskinlæringsmodeller, samt forvalte disse i produksjon.
For å sikre at modellene lærer seg det vi ønsker fra treningsdataen er god datakvalitet avgjørende. God datakvalitet er dessuten nødvendig for at de trente modellene skal kunne gi presise, robuste prediksjoner på ny data.
Peter Sandberg, Bouvet. Data scientist, utvikler og løsningsarkitekt i prognoseprosjektetUtviklet et rammeverk for MLOps
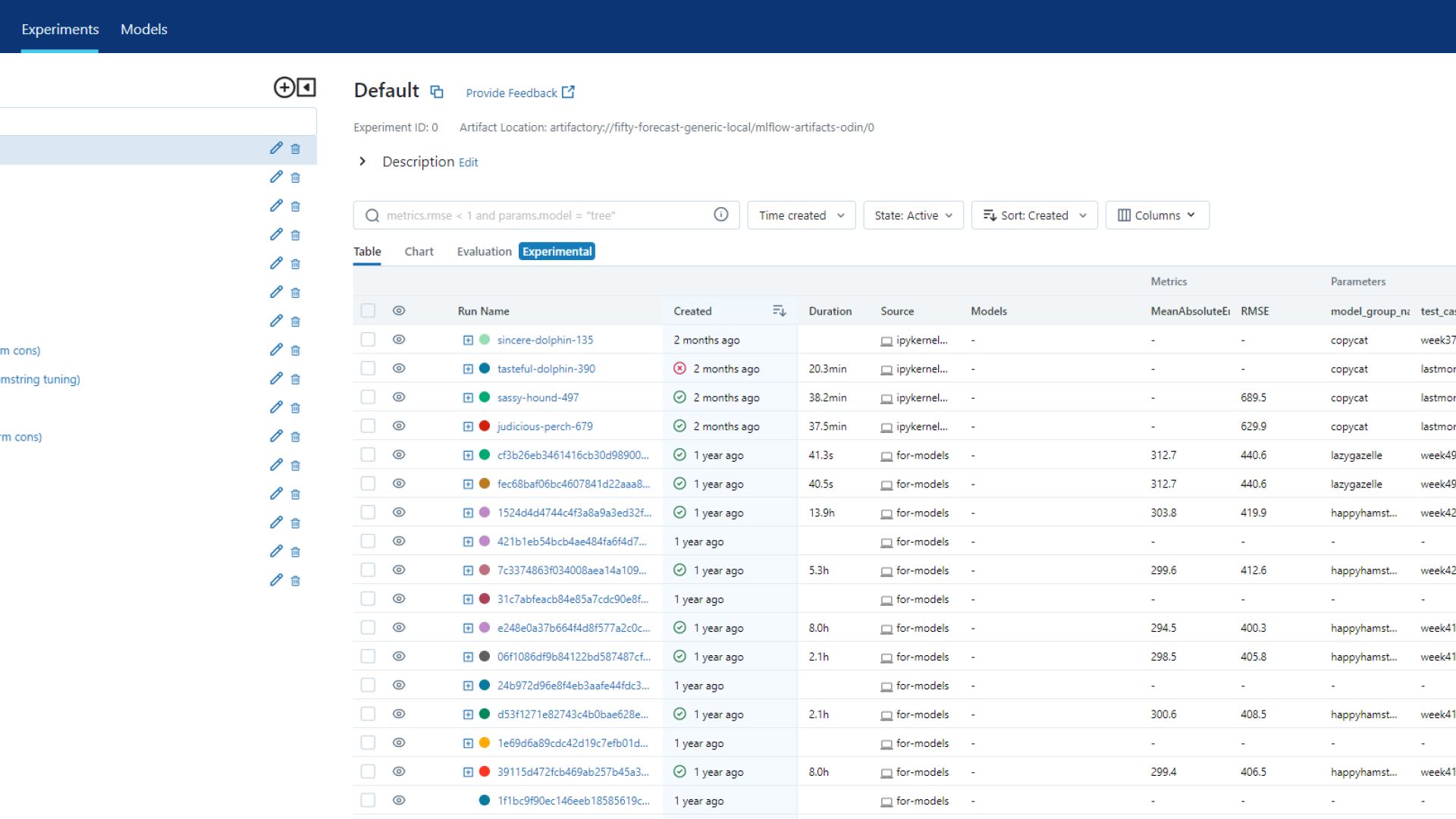
Bouvet og Statnett har utviklet et rammeverk for maskinlæringsmodeller, basert på blant annet MLFlow. Rammeverket benyttes aktivt i prosjektet for å trene og konfigurere maskinlæringsmodeller, samt dokumentere hvordan hver modelliterasjon ble skapt.
Flere typer modeller er testet ut
Flere typer maskinlæringsmodeller, inkludert dyp læring er blitt testet ut for å finne ut hva som gir de beste resultatene. De beste resultatene ble oppnådd ved bruk av Ridge Regression, Gradient Boosting og Random Forest.
Datakvaliteten er helt avgjørende for gode resultater
I arbeidet med modellene har prosjektteamet vært opptatt av sikre kvaliteten på dataene og kontinuerlig forbedret disse gjennom analyse og dataforskning. Ved hjelp av blant annet Python, scikit-learn og pandas har de benyttet eksplorativ dataanalyse og statistisk modellering for å utforske datakvaliteten samt feature engineering for å bearbeide dataene slik at modellene kan lære av dem.
Datavisualisering brukes for å kommunisere analyseprosesser og resultatene, slik at disse kan deles med andre dataforskere, domeneeksperter og andre interessenter.
Automatiserte prosesser sørger for at modeller i produksjon trenes på nytt hver uke
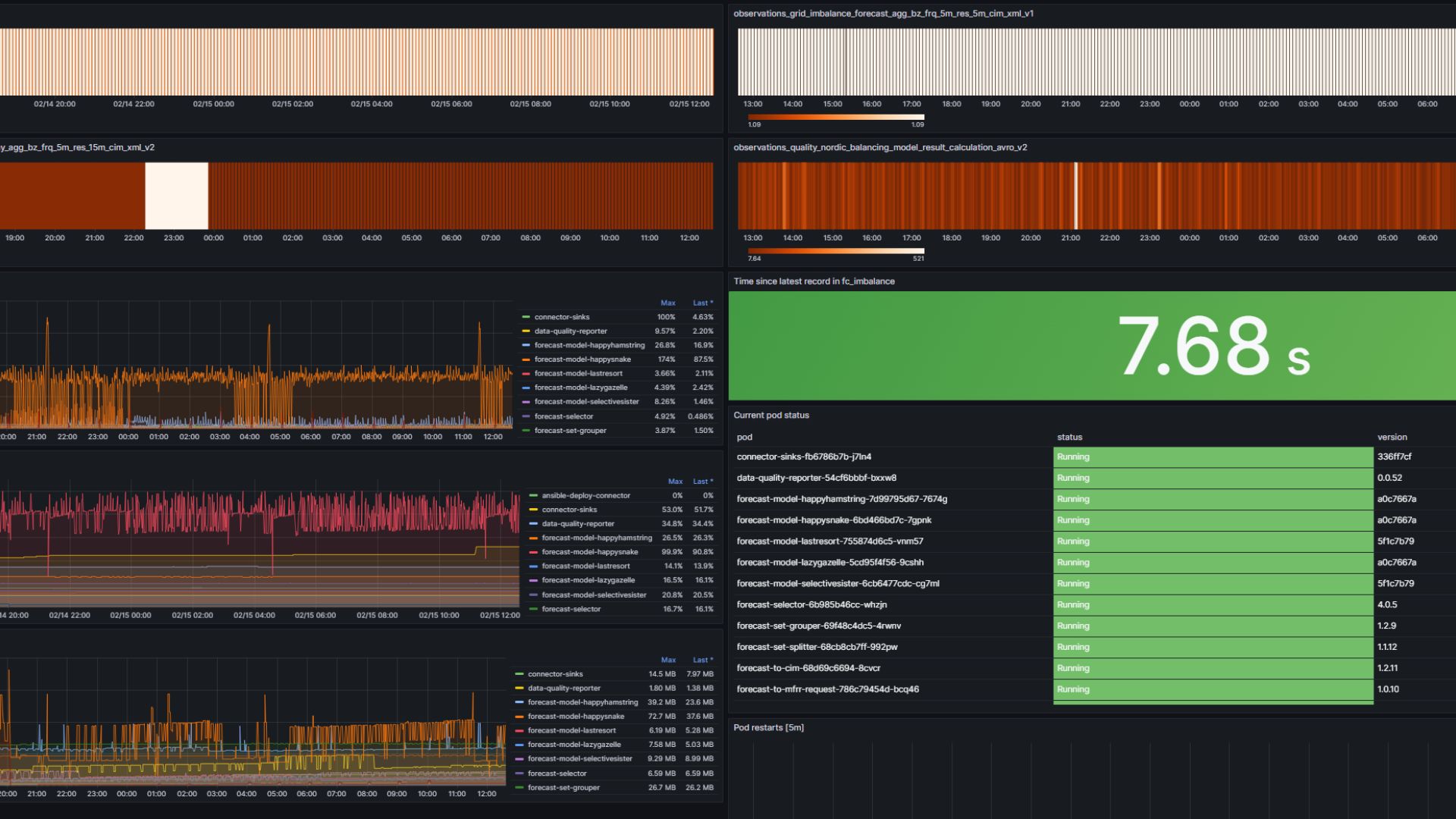
Modeller som er i produksjon, blir trent på nytt hver uke som en del av en automatiserte bygg- og deploy pipeline basert på GitLab pipelines. Dette sikrer at modeller alltid er oppdatert med fersk treningsdata. Treningsdata hentes fra en PostgreSQL database, som kontinuerlig oppdateres med ny data fra Kafka. Data fra databasen brukes også for å gjøre evaluering av modeller og metoder manuelt, utenfor de automatiserte omtreningene.
Grafana, Splunk og Prometheius brukes for monitorering og oppfølging av modeller i produksjon.
Python er språket
Python er kjerneprogrammeringsspråket i prosjektet, og python-biblioteker som benyttes inkluderer scikit-learn for maskinlæring og PyTorch for dyp læring. Pydantic for data¬validering og PyTest for automatisert testing. Jupyter Notebooks benyttes for dokumentasjon og visualisering av analyseprosessen og resultatene, slik at disse kan deles med teamet og andre interessante.
Veien videre
Modellene er nå rullet ut i produksjon, og brukes som beslutningsstøtte for operatørene på landssentralen. Prosjektet jobber nå tett med operatørene for å forbedre eventuelle svakheter de skulle oppdage i denne fasen, svakheter ved presisjonen til prognosene og ved robustheten til løsningen.
Fra og med neste år går prosjektet over i en ny fase, hvor prediksjonene fra modellene går fra å være beslutningsstøtte til å være del av en helautomatisert sløyfe for balansering av strømnettet. Det er derfor viktig at presisjonen og robustheten blir så høy som mulig før den tid.
Ubalanseprognose er avgjørende for automatiseringen av Statnetts balansering. Den forutsier ubalansen mellom kraftproduksjon og forbruk, og hjelper med å opprettholde balanse i kraftsystemet. Hvert 5. minutt vil Statnetts ubalanseprognose forutse hva prognosen vil være de neste to timene Ved hjelp av maskinlæring og bedre datakvalitet har Statnett utviklet et verktøy som er klart til å inngå i grunnmuren for fremtidens kraftsystemdrift.
Eivind Lindberg, spesialrådgiver StatnettDisse tjenestene ble benyttet i leveransen
- Teamledelse
- Etablering av rammeverk for utvikling
- Etablering av rammeverk for forvaltning
- Tekniskarkitektur
- Informasjonsarkitektur
- Design av maskinlæringsdatamodeller
- Deployment mellom miljøer
- Forvaltning av løsning
- Statistisk analyse
- Løsningsarkitektur
- Scrum-metodikk
Følgende teknologi ble benyttet leveransen
- MLFlow
- Git
- Python
- JIRA
- PyTest
- Splunk
- Grafana
- Jupyter Notebooks
- Kafka
- Artifactory
- Poetry
- Maven
- Openshift
- Ansible
- SonarQube
- Prometheius
- PostgreSQL
Lurer du på noe? Ta gjerne kontakt



