Roles you'll need in your successful Data Science team
When talking about Data Science a lot of people overlook the fact that the Data Scientist is a just a single role in the Data Science team. In this article I'll outline the four basic roles required for undertaking any Data Science project.

Background
Over the last year I've been building up a team of Data Scientists here at Bouvet's Oslo office. During this process I've learnt quite a lot about what makes a successful Data Science project. And the most valuable lesson has been that multiple roles (or competency areas) are required.
Note that one person can assume more than one of the roles I outline below, depending on the details of your project.
Role 1: The Data Scientist
Ok, so this one is pretty obvious. Almost every Data Science project will need a Data Scientist, that unicorn who has mad skills in computer programming and mathematics, in addition to outstanding domain knowledge!
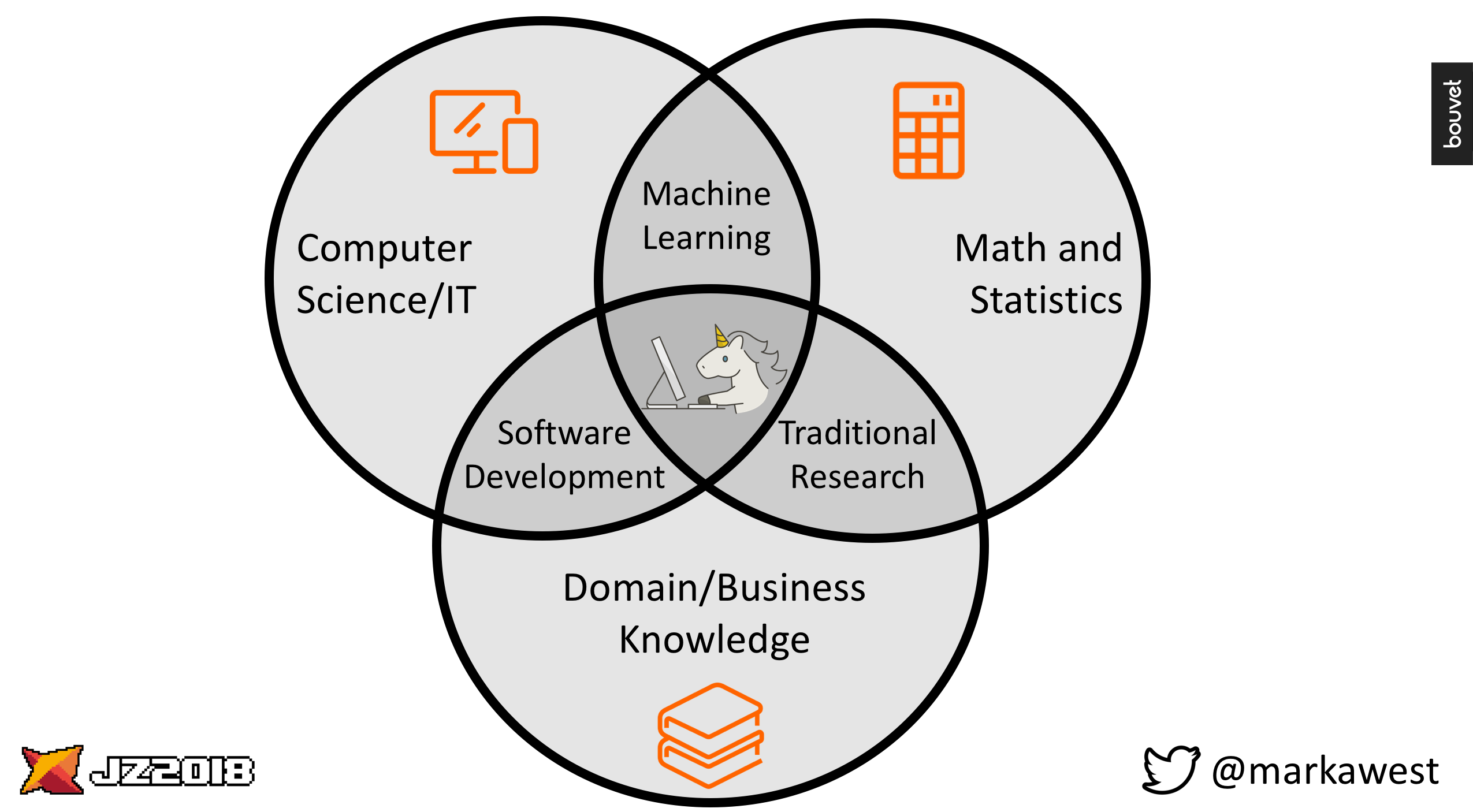
A Data Scientist does the following:
- Defines, proves and disproves hypotheses. Data Science often uses the scientific method, where hypotheses and observation define the scope of the project. A good Data Scientist will be able to tell you if your hypothesis provides a realistic basis for your project.
- Gathers information and data. Via discussion with system owners and Subject Matter Experts the Data Scientist will build their Domain knowledge and identify data sources they will use in the project.
- Data wrangling. This is a large part of the Data Scientists job, and concerns both understanding the data itself, and forming the data into a format that the Data Scientist can work with. A key task here is Feature Engineering.
- Builds, tunes and tests algorithms and models. Which algorithm shall we use? How should the algorithm be tuned? How do we interpret the output? A good Data Scientist will be able to identify specific algorithms and models, rather than just trying random ones.
- Communicates the result. The Data Scientist needs to be able to explain their methodologies and results to a wide range of profiles. This requires good communication skills.
Good Data Scientists are hard to find, especially ones with consultancy skills and the ability to adapt to new projects!
Role 2: The Data Engineer
Data Engineers are a slightly different beast, and normally come from a pure IT background. They are the ones that build the infrastructure that enables the Data Scientist to do their job.
A Data Engineer has a range of roles:
- Build Data Driven Platforms. This includes Data Warehouses, Data Lakes, streaming platforms and other solutions that gather or aggregate Data and make it available to the Data Scientist. A good Data Engineer will have an overview of Cloud based solutions in addition to more traditional architectures. They'll also be pragmatic in their choice of solution - we are not all Netflix!
- Operationalize Algorithms and Machine Learning models. You'd be surprised how many projects forget this step until it's too late! How do you get your scikit-learn machine learning model into production? How will the model be updated? How will we know if the model starts performing under requirements due to the data changing over time? All these questions need to be addressed right from the start of the project and require discussion between the Data Engineer, the Data Scientist and the project's stakeholders.
- Data Integration. Where the Data Scientist identifies the Data Sources they want to get information from, the Data Engineer implements the integration to make this Data available. Good Data Engineers will work with the Data Scientist to make sure that any required data aggregation or transformation is also handled in this step.
A good Data Engineer is worth their weight in gold, and are just as vital to the project as the Data Scientist!
Role 3: The Visualization Expert
It's probably no shock when I state that we process images much faster than words. Replace words with terabytes of data and the need for a visual representation is even more acute.
In a Data Science project the Visualization Expert will generally help with, amongst other things:
- Storytelling. A Visualization Expert is key in helping the Data Scientist communicate their methodologies and findings in a intuitive manner.
- Build Dashboards and other Data visualizations. In addition to making information simpler to process, the Visualization Expert will take design principals into account. This might include universal design requirements, supporting the users workflow and finally avoiding information overload.
- Provide insight through visual means. Sometimes even the Data Scientist needs help from the Visualization Expert to understand their data. This is especially helpful when the Data Scientist is initially exploring the data.
Never undervalue a good Visualization Expert. They are the secret sauce to helping your Data Science project succeed! And if you are still unsure, have a look at some of these interactive Data Visualizations.
Role 4: The Process Owner
Here I am in danger of stating the obvious. Every project needs an owner or manager, right? Of course! But I'd argue that the Data Science Process Owner has some extra things to be aware of, in addition to standard Project Management tasks.
-
Project Management. That we are doing Data Science does not remove requirements for reporting, planning and ensuring progress!
-
Manage stakeholder expectations. Data Science projects are often exploratory by nature. I'd argue that 60-80% of a Data Science project will involve gathering the data and then massaging it to work out what secrets it contains. Someone therefore needs to ensure that stakeholders are aware of this and don't become frustrated by a perceived lack of progress. Informing stakeholders of any small insights we get during this phase can be useful.
- Maintain a Vision. It is easy for a project's scope to shift as we learn more about the data and the domain. This is fine as long as stakeholders understand and accept any change to scope. A Process Owner needs to continually inform stakeholders of progress and attain acceptance for any deviation. If no acceptance is forthcoming the Process Owner will have to ensure that the team delivers as originally agreed. No matter what, all team members should always be aware of the projects goals.
- Facilitate. We mention some examples of facilitation above, but there are many more. Facilitation between team members, talking to system owners get access to the data, and removing impediments are all typical Process Owner tasks.
Summary
This blog can be summed up in this slide, which like the others in this article is borrowed from my upcoming JavaZone 2018 talk - "A Practical-ish Introduction to Data Science":

It is possible to argue for additional roles in a Data Science project. The Data Engineer role can be split into an Architect and Developer role, for example. And where is the Subject Matter Expert?
All fair points! My list isn't meant to be exhaustive, but to illustrate the need for additional competencies in your Data Science project.
If you come up with examples of additional roles then please feel free to discuss them in the comments section below or on Twitter. I'm always learning, and would love to hear other peoples opinions and experiences from real life projects!
Thanks for reading!
Mark West currently manages the Data Science team at Bouvet Oslo.

Statens Vegvesen
Flere grønne reiser i Bergen

Agder Energi Nett
Skalerbar stordataplattform gir store innovasjonsmuligheter

NTNU
Ny læringsplattform for Norges største universitet

eSmart
Overvåker strømnettet med kunstig intelligens og Azure

Brønnøysundregistrene
Enklere og mer brukervennlig Altinn

Viking