Estimering av produktkøen med T-skjortestørrelser
I Scrum må vi også tilfredsstille oppdragsgiver og ledelsens behov for en ferdigdato eller tidspunkt for release. Da kommer vi ikke unna estimering av omfang, men hvordan kan vi gjøre det uten at vi blander inn for mange forhold som strengt tatt ikke har så mye med ferdigdato å gjøre?

For å kunne komme opp med et nogen lunde vettugt estimat på ferdigstilling, er prinsippene og tankegangen i Scrum at vi holder pådrag (ressursbruk) og omfang (scope) så stabilt og konstant som mulig. Med et stabilt team og stabile rammebetingelser vil vi etter hvert også kunne få en omtrentlig implementeringshastighet (velocity) på teamet det går an å bruke for å si noe fornuftig om når vi kan være ferdig med produktkøen (produktbackloggen). Vi må imidlertid ha et godt organisert og oversiktlig omfang å jobbe med - som både lar seg dele opp i mindre enheter (user stories eller brukerhistorier) og som lar seg estimeres i størrelse. Men hvordan skal vi gjøre dette for å kunne gjøre ferdigstilling litt mer forutsigbart?
Fra Scrum-kurset (CSM) lærte jeg at en produktkø er en prioritert liste med funksjonspunkter (brukerhistorier) bestående av navn, relativ størrelse og prioritet. I tillegg til dette kan det være greit å ha med en identifikator samt en kort beskrivelse av hvordan produkteier forventer at denne funksjonaliteten skal demonstreres.
I praksis er dette gjerne noe mer komplisert. I langt de færreste tilfellene har jeg sett team som jobber sammen med en erfaren produkteier og bygger opp en godt strukturert produktkø fra bunnen av. I mange tilfeller er produktkøen gjerne generert ut fra et sett med krav, eller gjerne feilrapporter som ikke er viktige nok til å bli håndtert umiddelbart. I prosjektet jeg jobber i nå, kom jeg inn etter at teamet, og produkteier hadde kjørt et par sprinter og hadde en produktkø som ikke lot seg sortere, hadde overskrifter og innrykk og som heller ikke var beskrevet slik at all informasjonen kunne samles på en linje. Dette gjorde produktkøen lite oversiktlig og vanskelig å arbeide effektivt med.
Det at alle i teamet delvis hadde estimert backloggen i ukeverk fikk meg til å tenke på en del artikler som blant andre Mike Cohn hadde skrevet om estimering, feilkilder og problemer med det. Det var og er min klare oppfatning at vi så langt det er mulig bør holde oss unna noen som helst slags estimering i tid for å redusere feil og forbehold blant annet. Jeg foreslo derfor at vi like greit kunne estimere produktkøen i T-skjorte størrelser slik at dette ble et radikalt skifte i hvordan teamet forholdt seg til størrelsen på hvert enkelt funksjonspunkt (Backlog Item).
I Backlog Grooming lagde vi derfor små kort av Post-It lapper som vi klistret sammen back-to-back og skrev T-skjorte størrelser på dem. Når teamet estimerte størrelsen på en brukerhistorie, benytter vi Poker-planning slik vi også ville benyttet en poker-planning kortstokk med modifisert fibonacci rekke. Hver enkelt i teamet plukker et kort, og holder det skjult til alle andre i teamet har funnet sitt kort. Alle viser sitt kort samtidig til de andre og større forskjeller i estimat benyttes som et utganspunkt for en kort diskusjon om brukerhistorien. Teamet samles relativt raskt til et felles estimat som noteres i produktkøen.
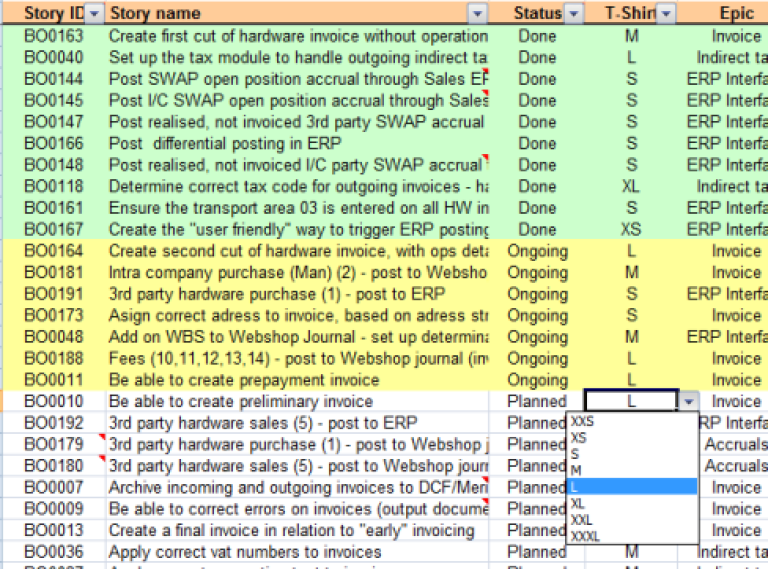
Ulempene med T-skjorte størrelser av brukerhistorier er at disse ikke lar seg summere eller regnes så mye på. Jeg må derfor lage en omregning fra T-skjorte til numeriske poeng. Dette løste vi fint ved å legge inn en (normalt skjult) kolonne i regnearket.
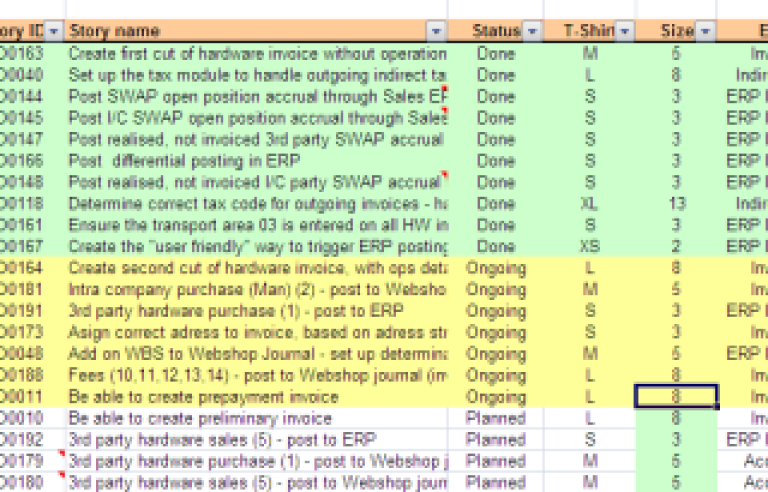
Med data som dette er det brått mulig for oss å føre en viss statistikk over hvor mye av produktkøen som faktisk ferdigstilles hver sprint. Dette kan gi oss en graf som f.eks. denne:
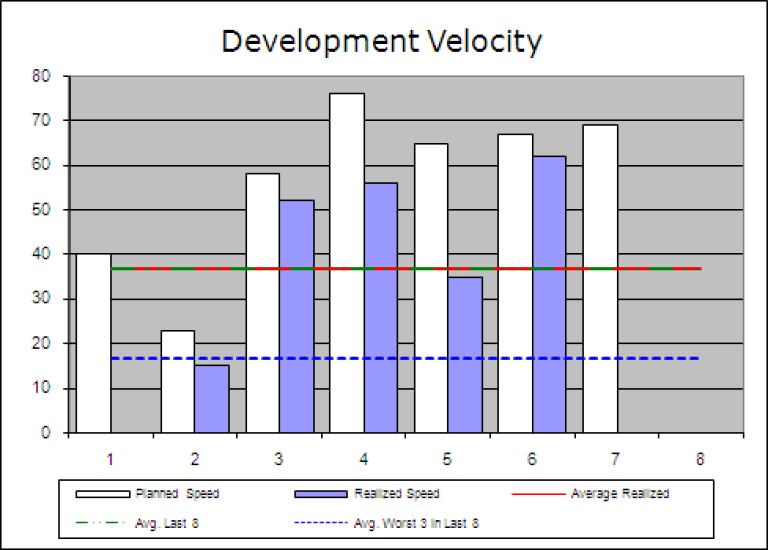
Her ser vi at teamet i første sprint ikke fikk gjort stort, og fikk faktisk ikke ferdigstilt noen verdens ting. Dette er normalt (skjer oftere enn ikke i nye team og nye prosjekter) og handler om at teamet tar inn over seg hva Definition of Done (ferdigdefinisjonen - DoD) egentlig betyr. Gradvis øker teamets presisjon på hva de planlegger (hvite søyler) og hva de faktisk får ferdig (blå søyler). I diagrammet over har de planlagt nesten 70 i inneværende sprint (sprint 7). Når vi nå vet hvor mye av produktkøen som til enhver tid er ferdig er der også enkelt å sette opp et nytt diagram: Release burndown:
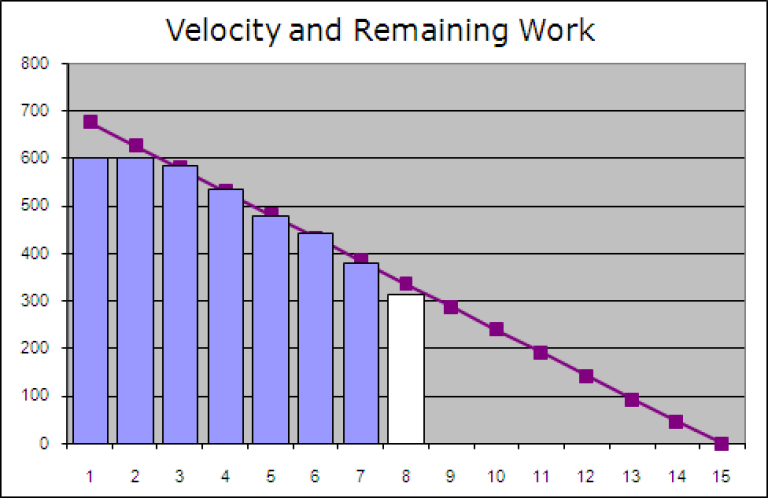
Her bruker Excel gjennomsnittet av de siste 3 sprintene for å beregene en sprint hvor hele produktkøen er ferdigstilt. Vinkelen på den fiolette linjen angir i praksis teamets utviklingshastighet (velocity), de blå søylene angir faktisk gjenstående omfang av produktkøen etter sprint og den hvite søylen angir gjenstående etter planlagt sprint dersom det planlagte fullføres i sprinten. For å konkludere ser vi altså at vi kan oppnå en rimelig troverdig plan på ferdigstilling på tross av at omfanget estimeres med T-skjorte størrelser.
Excel regnearket som er benyttet kan du laste ned her.




