6 Tips For Getting Started With Machine Learning
It's easy to burn time, money and the good will of stakeholders when starting with Machine Learning. In this article I give 6 tips that can help save your Machine Learning project before it has even begun!

Introduction
There is a lot of hype around Machine Learning and a lot of misinformation. This increases the risk of Machine Learning projects failing due to unreasonable expectations, lack of skills and incorrect choice of use cases.
To help you avoid some of the most common errors I've put together the following tips. They are technology agnostic and focus on what you'll need to have in place before any code is written.
The tips are as follows:
- Understand what Machine Learning is.
- Know the common applications of Machine Learning.
- Know the competencies that Machine Learning requires.
- Understand the Machine Learning process.
- Machine Learning is a team sport!
- Start simple and be prepared to invest.
Tip 1: Understand what Machine Learning is
Machine Learning is all about enabling computers to build their own rules for working with data, without being explicitly programmed. The difference between Machine Learning and Traditional Programming is summed up in the following diagram:
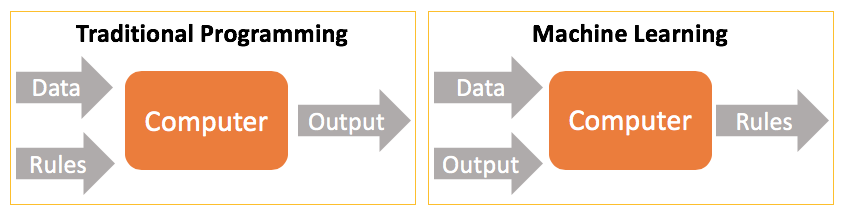
Traditional Programming requires a developer to manually define the Rules for processing your Data. In Machine Learning the computer creates it's own Rules based on the Data and optionally your historical Output data.
The creation of Rules in Machine Learning is performed by the application of algorithms and applied statistics. These algorithms allow Machine Learning to find patterns in your Data, which then can be used to give insight and predict new Output's.
Machine Learning is often conflated with Artificial Intelligence or Deep Learning. But how do these terms actually relate to one another?
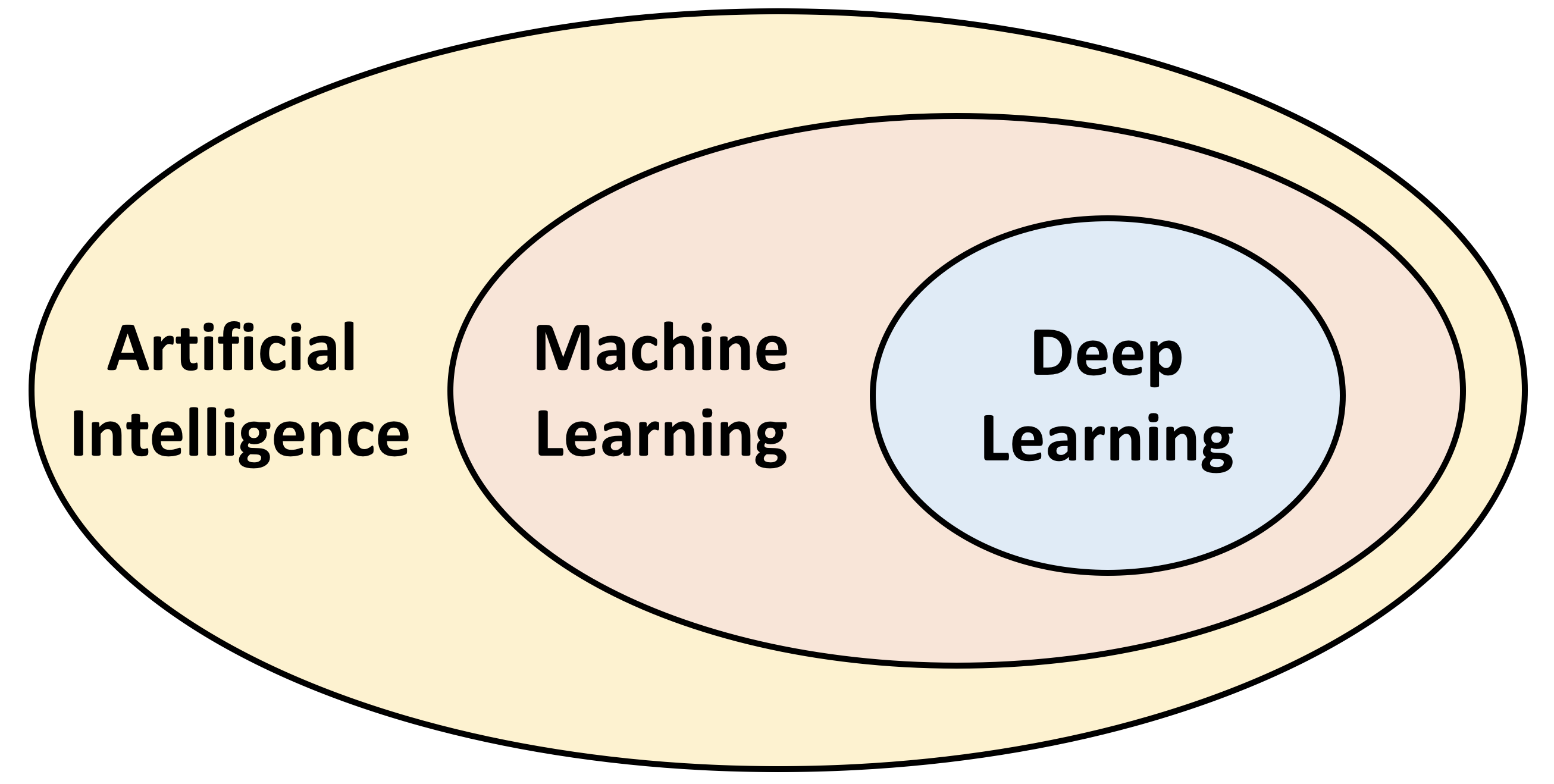
As you can see, the terms are hierarchically linked:
- Artificial Intelligence is a blanket term covering all efforts to enable computers to exhibit human-like intelligence. At this level, we are talking about psychology (understanding the brain) and philosophy (what is intelligence) in addition to technological research.
- Machine Learning is a specialization of AI, focusing on the application of statistics and algorithms to data to allow computers to build their own rules for processing data.
- Deep Learning is a specialization of Machine Learning that is inspired by the brains architecture. As such it focuses on the application of "deep" or "multi-layered" neural networks.
Why are these distinctions important to understand?
- Avoid using the term Artificial Intelligence as it is too broad. If a vendor or team member begins to talk about AI, ask them to be more specific - they may be trying to sell you snake oil.
- Deep Learning is at the cutting edge of Machine Learning. As such it can carry more risk and is possibly not the best place to start your Machine Learning journey.
- Deep Learning models are often black box solutions. In other words, it can be hard to get insight into why a Deep Learning model gives a certain result. This can make Deep Learning incompatible with use cases where insight may be legally or morally required.
- Machine Learning is more than Neural Networks and Deep Learning! There are many well proven and well-understood algorithms that allow insight and solve business problems without the application of Neural Networks.
Tip 2: Know the common applications of Machine Learning
The next step is to understand what you can actually achieve with Machine Learning. To do this you should know the three basic types of Machine Learning outlined below:
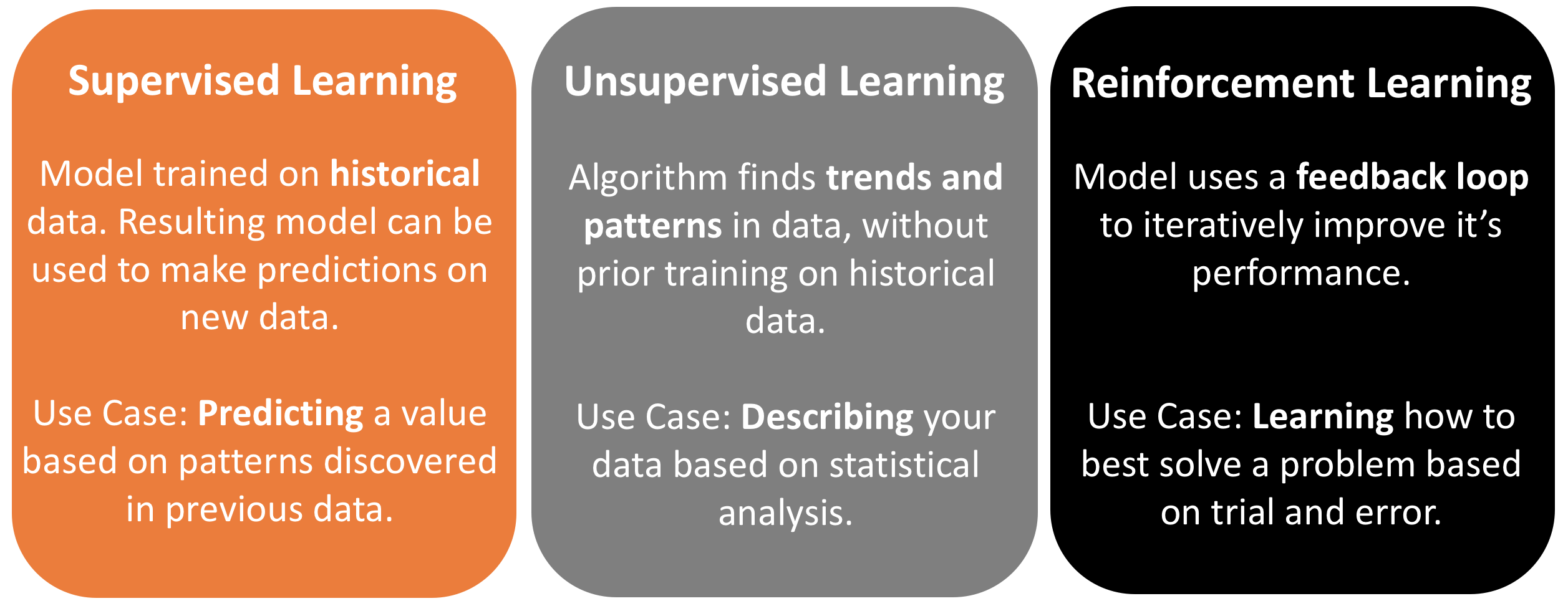
To further explain:
- Supervised Learning is about predicting new outcomes, based on historical data. A supervised learning model will attempt to find the correlation between your historical data inputs and outputs. Use cases might include predicting house prices, finding objects in images and translation of documents.
- Unsupervised Learning is about describing your data. The model uses statistical analysis to find patterns in your data, according to the data's own attributes. Use cases might be finding new customer segments in your sales data or document classification.
- Reinforcement Learning provides a dynamic model that is constantly trying to improve its own performance through trial and error. Over time the model improves it's strategy and gets better and better - just like someone playing a game. Use cases include stock trading and inventory management.
Why is all of this important? By understanding the common applications you can begin to understand how Machine Learning can be applied to your organization! I would personally begin by looking into Supervised and Unsupervised Learning. Reinforcement Learning is pretty hardcore, and you'll need a lot of data!
Tip 3: Know the competencies that Machine Learning requires
As mentioned earlier in this article, Machine Learning is the application of algorithms and statistics to data. Therefore, In order for your Machine Learning initiative to be successful, you'll need to have access to the correct skills. The following diagram illustrates this:
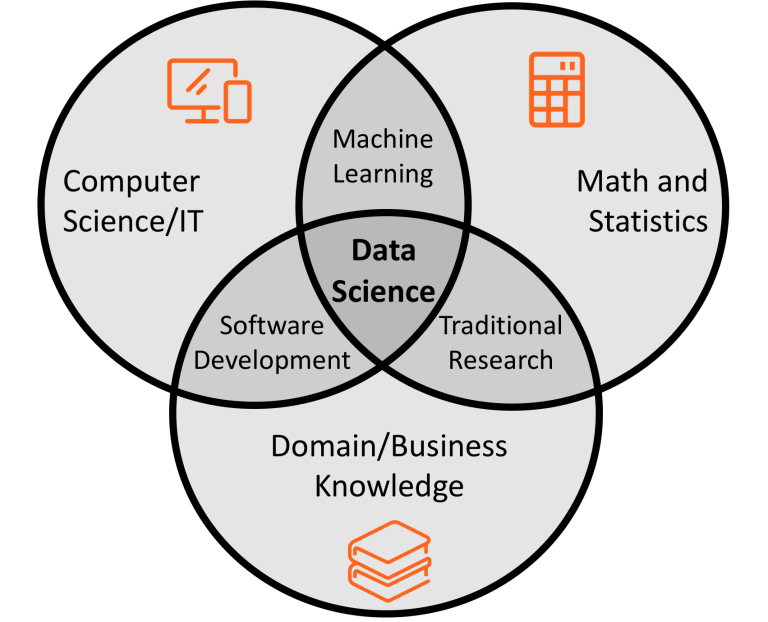
A common mistake is to under-evaluate the importance of the Math and Statistics knowledge when working with Machine Learning. The success of your initiative will depend on choosing the correct algorithm for your solution, knowing how to massage your data and finally correctly tuning the hyperparameters of your chosen algorithm. These tasks all require a solid grounding in Math and Statistics.
When working with Machine Learning I strongly recommend that you have a Data Scientist on board.
A good Data Scientist will have the combination of skills described above, and often have a different academic background to Computer Scientists. The Data Scientists at Bouvet Oslo include Astrophysicists, Mathematicians, and Statisticians, all of whom possess solid programming skills in addition to strong Math and Statistics knowledge.
The role of the Data Scientist becomes even more clear when one looks at the process for working with Machine Learning.
Tip 4: Understand the Machine Learning process
A Machine Learning project will normally go through the following steps:
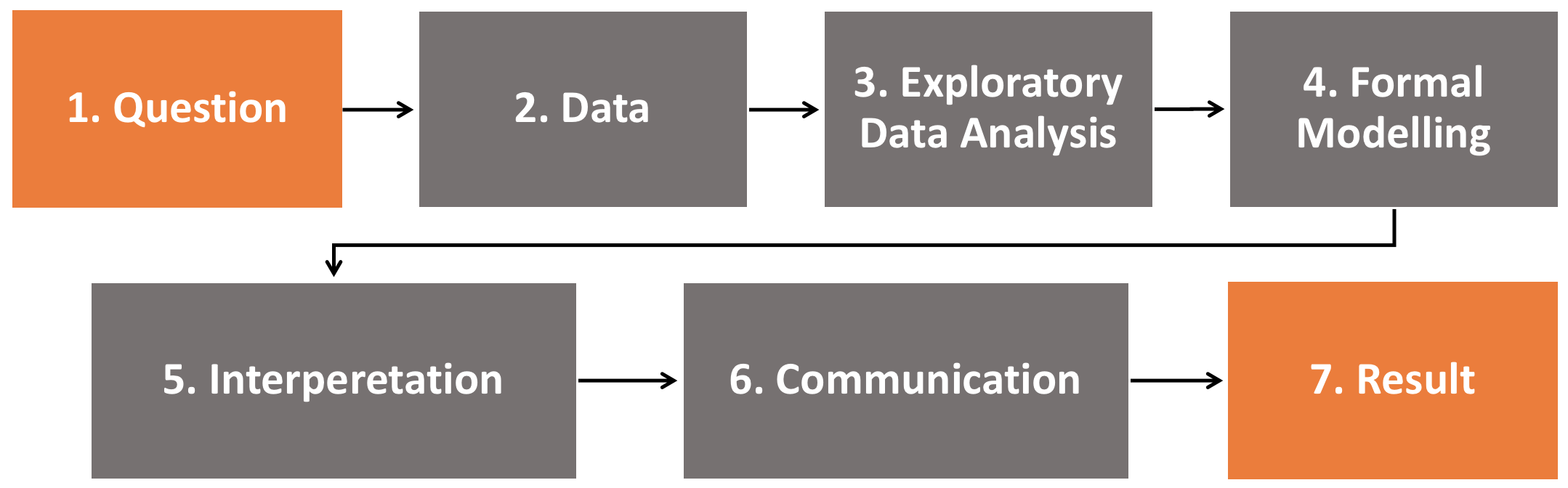
This process is an amalgamation of the common steps that can be found in many Data Science / Machine Learning processes, such as Crisp DM, Microsoft's Team Data Science Process and Bouvet's own Data Science Methodology.
The steps are as follows:
- Question. Any Machine Learning project should start with a Question or Hypothesis. What is it that we are trying to achieve? Don't be afraid of being too specific here. The Question can always be updated if we learn more as the project progresses. A good Data Scientist will ensure that the Question or Hypothesis is one that Machine Learning can answer.
- Data. The next step is to gather our data. This can take time, as we may need to aggregate data from many different sources. Or perhaps we need to secure permission from system owners. At this point, we may not know exactly what kind of data we have, or how good the data quality is.
- Exploratory Data Analysis. Once we have our data we need to understand it. By applying statistical methods and visualizations to the data, your Data Scientist will start to understand how the data fits together. Can we answer our hypothesis with the given data? Do we need to address missing or contradictory data?
- Formal Modelling. Finally, your Data Scientist is ready to create a final Machine Learning Model! By this point, they should have a good idea of which algorithms they wish to try out.
- Interpretation. After creating your Machine Learning Model you'll need to understand what it gives you. It may be that the result is not as expected. Using their knowledge of the algorithm underlying the model, your Data Scientist will be able to explain the result of your project.
- Communication. Here the Data Scientist will report and communicate the results to your stakeholders. This will require the Data Scientist to communicate the result in layman's terms, without sinking into jargon!
- Result. Congratulations, you have reached the end of the process. Now it is time to evaluate the results and apply what you have learned in your next project!
Some more notes on this process:
- Step 1 requires the Data Scientist to build up Domain and Business Knowledge.
- Steps 1-3 take up 60-80% of the Machine Learning projects time!
- Exploratory Data Analysis (Step 3) can also use Machine Learning to give insight into the data's hidden patterns. It will also use statistical methods such as Feature Engineering.
- Creating a formal Machine Learning model (Step 4) is just a small part of the entire process.
- The process is iterative, allowing looping between all steps. For example, you may find out that you need to go back and fetch more data after step 3, or that you need to re-evaluate your original hypothesis.
You may have noticed that this process doesn't mention deploying the model. That's because I chose to focus on the Data Scientists job. Deployment is someone else's job - as described in the next section!
Tip 5: Machine Learning is a team sport!
A common mistake is to focus on recruiting Data Scientists to your Machine Learning team, without thinking of the other roles that are required.
But how will you get your Machine Learning algorithm in production? Who will build your data pipelines? What about visualizing the results? How will you ensure that your team members get the support it needs? And what about evangelizing the team and its results in your organization?
To address these myriad concerns, I would argue that any Machine Learning project has at least the following 4 roles:
- Data Scientist - builds your Machine Learning Models.
- Data Engineer - deploys and monitors your Machine Learning Models. Also works with data integration.
- Data Visualisation - creates dashboards and data insight.
- Process Owner - manages the team, manages stakeholder expectations and maintains a vision.
These roles are summed up in the below image and discussed in more detail in my previous article about Data Science teams.
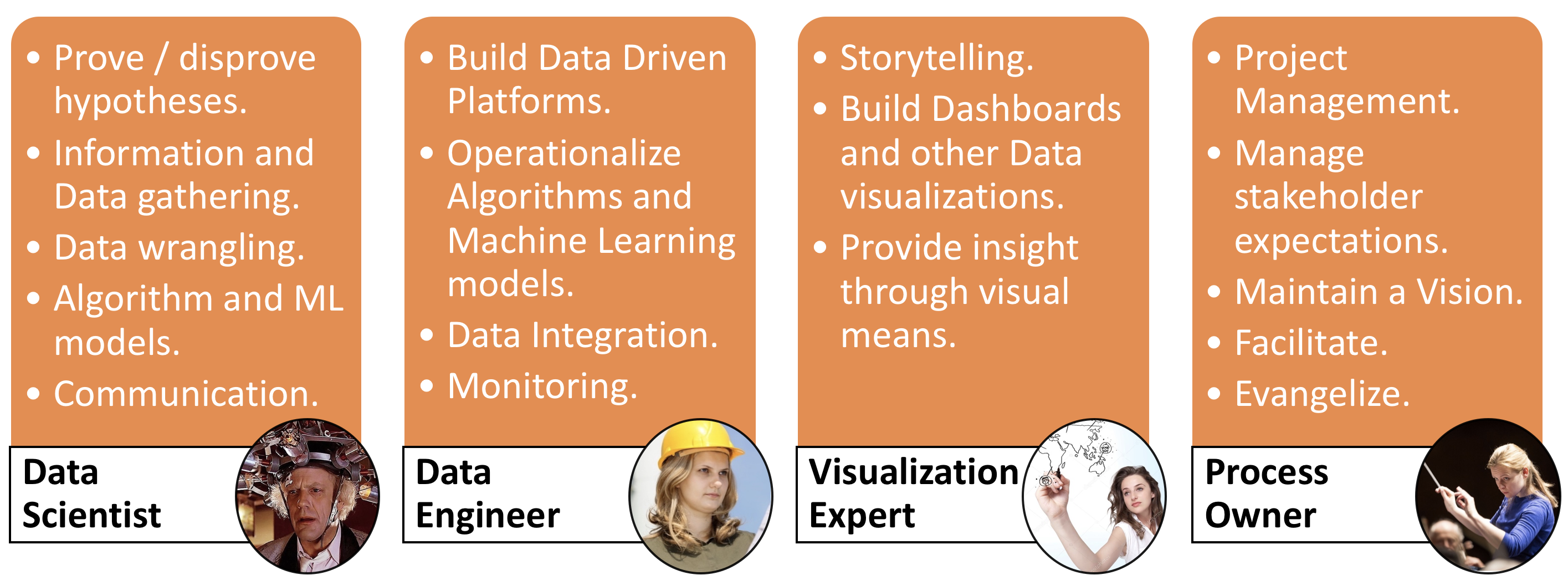
Of these roles, I would argue that the Data Engineer role is currently the hardest one to fill in today's market - and also the easiest way for a Computer Scientist to get involved in Machine Learning.
Tip 6: Start simple and be prepared to invest
When starting out with Machine Learning you need to accept that it is hard and that there are no guarantees that your specific hypothesis or use case can be solved with Machine Learning.
Aim for the low hanging fruits. Find a simple use case and try to solve it with simple algorithms such as Linear Regression, Decision Trees or K-Means Clustering. By doing so you can test your team and your process to see if everything works as planned. Make the necessary adjustments and try again.
If your initial projects fail, don't be disillusioned. Turn your failures into a learning process. If the initial projects succeed, build up to more advanced use cases and Machine Learning techniques.
Finally, remember that the Machine Learning Process (see Tip 4) takes time, especially the initial steps (i.e. defining a Question, collecting Data and Exploratory Data Analysis). Work with your team to identify quick wins along the way. Such quick wins can be communicated to the rest of your organization, giving the team a positive reputation and increasing their motivation.
Summary
In summary, my 6 tips for getting started with Machine Learning were:
- Understand what Machine Learning is.
- Know the common applications of Machine Learning.
- Know the competencies that Machine Learning requires.
- Understand the Machine Learning process.
- Machine Learning is a team sport!
- Start simple and be prepared to invest.
Addressing these early will give your Machine Learning initiative a solid start.
Do you disagree with my suggestions? Or perhaps you have something to add? Feel free to add your opinion in the comments below! Alternatively get in contact if you would like to talk more about Machine Learning or Data Science!
Thanks for reading!!
Mark West leads the Data Science team at Bouvet Oslo. In his spare time, he also leads the Norwegian Java User Group.

Statens Vegvesen
Flere grønne reiser i Bergen

Agder Energi Nett
Skalerbar stordataplattform gir store innovasjonsmuligheter

NTNU
Ny læringsplattform for Norges største universitet

eSmart
Overvåker strømnettet med kunstig intelligens og Azure

Brønnøysundregistrene
Enklere og mer brukervennlig Altinn

Viking