Kvalitetssikring for "Natural Language Processing" prosjekter
I dette innlegget presenterer vi et enkelt flytskjema som vil gjøre det enklere å vite om ditt Natural Language Processing (NLP) prosjekt har et godt utgangspunkt eller om du bør ta en nøye vurdering før du setter i gang.

Hva er "Natural Language Prosessering" (NLP)?
NLP er et underfelt av språkvitenskap, informatikk og maskinlæring. Det fokuserer på hvordan man programmerer datamaskiner til å behandle og analysere store mengder naturlig (menneskelige) språk. Typiske problemstillinger vil være å kategorisere dokumenter i forskjellige kategorier, tolke graden av positivtet og negativitet i en tekst, finne likheter mellom tekster og automatisk tekstoppsummering.
Motivasjon
Basert på erfaringer fra tidligere prosjektet i Data Science-avdelingen i Bouvet Øst, har vi utviklet et flytskjema for å undersøke om et prosjektet er velegnet for NLP eller om man bør trå mer varsomt. Å følge dette flytskjemat vil kunne gjøre et NLP-prosjekt mer robust og gjennomførbart. Kan man svare "ja" på alle spørsmålene, vil man også spare mye tid, krefter og penger på blindveier. Vi ønsker derfor å dele våre erfaringer med andre som ønsker å sette i gang eller holder på med et NLP-prosjekt hvor man bruker maskinlæring.
Flytskjema
Flytskjemaet bør gjennomgås før man setter igang med et NLP-prosjekt. Det er etter vår erfaring altfor ofte at målet med prosjektet ikke er godt nok definert, eller at man ikke har de nødvendige dataene for å svare på problemstillingen man ønsker å løse. Dette gjelder spesielt for maskinlæring av tekster på norsk. Flytskjemaet kan brukes som en sjekkliste for å vurdere om et prosjekt har det godt fundament, må utarbeides mer eller heller bør settes på hyllen.
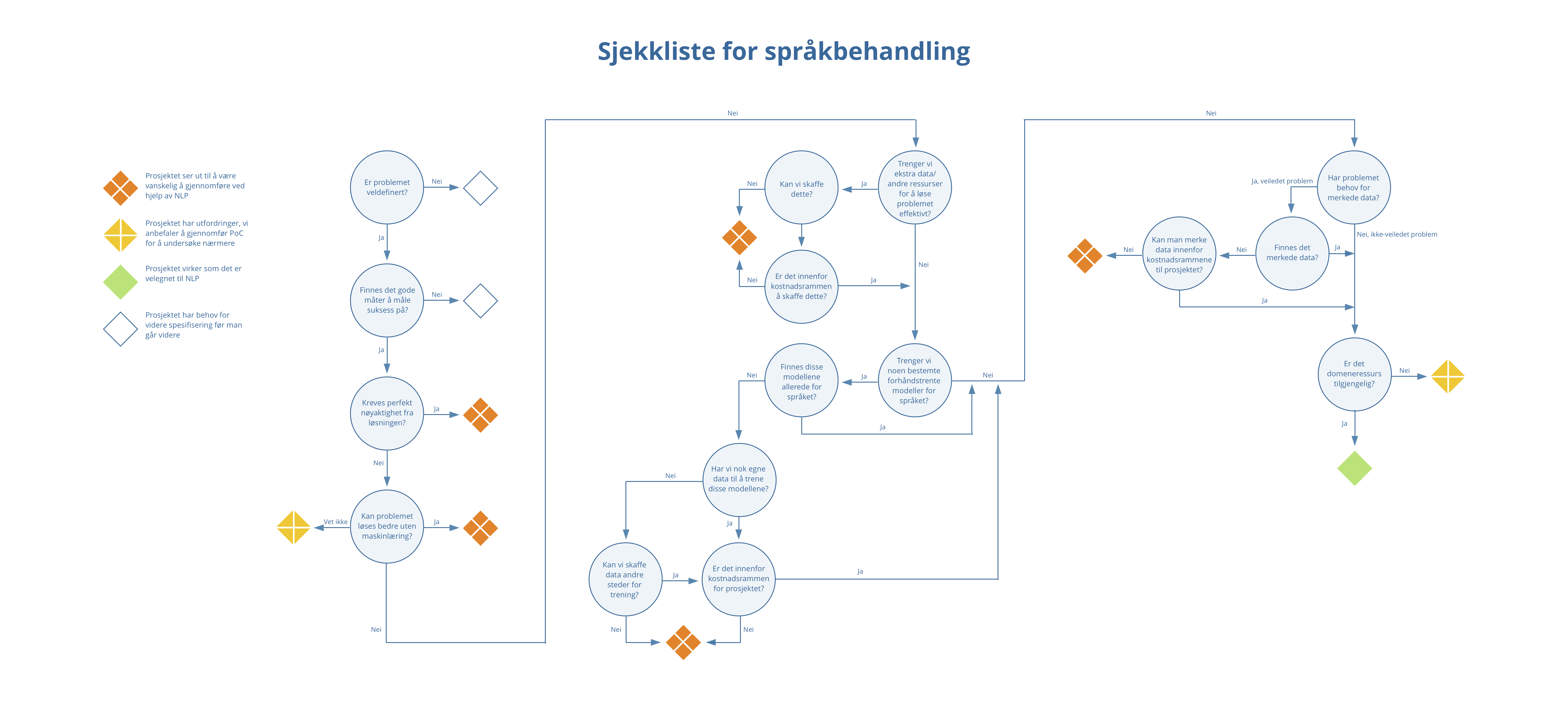
Under har vi utbrodert spørsmålene i flytskjemaet med flere detaljer.
Er problemet veldefinert?
Er det et klart mål med prosjektet eller ønsker du bare å undersøke mulighetene? Om det blir satt konkrete og presise mål er det mulig å sjekke fremdriften mot målet kontinuerlig. Det blir også lettere å gjøre vurderinger av data og veivalg ettersom det er et klart definert mål for prosjektet.
Finnes det gode måter å måle suksess på?
Om det ikke finnes gode måter å vurdere om et prosjekt er vellykket eller ikke, hvordan vet man at man er i mål? Hvordan vet man at modellen som er levert er et godt nok produkt til å gi merverdi for bedriften? I tillegg blir det vanskelig å måle kvaliteten av resultatene modellen produserer ettersom man ikke har definert en god måte å vurdere resultatene.
Kreve perfekt nøyaktighet fra løsningen?
Språk er ikke perfekt. Det vil alltid være en feilmargin. Spørsmålet er mer konkret, hvor høy er denne? Om det kreves nær perfekt nøyaktighet trengs det kanskje ekstra menneskelige ressurser for å sjekke kvaliteten. Perfekte resultater finnes dessverre ikke i den statistiske verden.
Kan problemet løses uten maskinlæring?
Det enkle er ofte det beste. Det gjelder også for med modeller. Det er ikke alltid nødvendig å bruke avanserte modeller, som kan kreve en stor datainnsamlingsjobb for å nå målet med prosjektet. Det bør derfor undersøkes om det finnes allerede eksisterende løsninger eller enklere modeller som løser problemet før man skyver løs med maskinlæring.
Trenger vi ekstra data / andre ressurser for å løse problemet effektivt?
Er det nok data for å løse problemet eller er vi nødt å skaffe disse dataene for å løse prosjektet? Vil dataene vi har kunne gi svar på oppgaven i prøver å løse?
Kan vi skaffe dette?
Er dataene tilgjengelig andre steder, eller må vi lage de selv?
Er det innenfor kostnadsrammen å skaffe dette?
Ethvert prosjekt har en ramme, en kostnad det tåler. Er det for kostbart å få tak i dataene vi trenger for å løse oppgaven trenger vi å undersøke et mindre datasett først før man går videre.
Trenger vi noen forhåndstrente modeller for språket?
Det finnes det færre trente algoritmer for norsk enn det gjør for engelsk. Dette er enda mer prekært for nynorsk. Det krever derfor mer undersøkelse på hva man trenger for å løse modellen og om det er mulig for det gitte språket. For eksempel, trenger man å trekke ut egennavn, eller dato for å kunne bygge videre på dette? Finnes det noen effektive måter for dette for norsk?
Finnes disse modellene allerede for språket?
Eksisterer det allerede modeller for språket vi ønsker å bruke?
Har vi nok egne data for å trene disse modellene?
Språkgrammatiske modeller krever mye data og eksempler for å gjøre en god jobb. Typisk har man ikke nok data for å gjøre denne jobben. Det vil også være et helt eget prosjekt i seg selv å gjøre denne modellen klar før man kan gå videre til det opprinnelige prosjektet.
Er det innenfor kostnadsrammen for prosjektet?
Ikke bare krever utvikling av språkmodeller mye data, men det tar ofte lang tid. Det vil gjøre at kostnaden for det opprinnelige prosjektet blir høyt. Spørsmålet er om man heller ønsker å vente på at det vil engang i fremtiden vil bli tilgjengelige slike modeller, eller ønsker å bruke ressurser for å utvikle dette selv.
Har problemet behov for merkede data?
De fleste prosjekter som kategorisering, følelsesanalyse osv. og ikke er eksplorative krever en fasit som algoritmene kan bruke som en mal. Hvis ikke vil vi ikke kunne måle resultatene av algoritmen eller hvor gode disse er. Vi er derfor tilbake til det andre spørsmålet i sjekklisten vår. Finnes det noen gode måter å måle modellen vår og dens resultater?
Finnes det merkede data?
Det er ikke utypisk at slike merkede data ikke finnes, eller at det ikke finnes tilstrekkelig i alle kategorier. Spørsmålet blir derfor om man skal begrense prosjektet til færre kategorier eller å genere disse dataene for å oppnå det som opprinnelig var ønsket.
Kan man merke data innenfor kostnadsrammen til prosjektet?
Å merke data er et manuelt og tidskrevende prosjekt. Noen prosjekt handler om å lage denne automatiske kategoriseringen og ikke et delmål i seg selv. Det krever derfor eksperter som bruker tid og krefter for å merke dataene korrekt. Dårlige merkede data vil igjen gi dårlige modeller.
Er det fagspesialister tilgjengelig?
Vanligvis er et prosjekt veldig spesifikt i forhold til et gitt område i språket, eller et fagspråk. Denne kunnskapen sitter som regel ikke de som utvikler modellene på og de vil derfor trenge støtte fra en intern ressurs for å validere modellene og resultatene.
Veien Videre
Om du klarer å svare godt på alle spørsmålene i flytskjemaet kan du være trygg på at du har et godt fundament for prosjektet ditt! Du sparer tid, penger og ikke minst pågangsmot med å ha gode definerte mål, riktige verktøy og nok av de riktige dataene.
Alle tilbakemeldinger angående vårt flytskjema eller om du ønsker et konkret input til akkurat ditt prosjekt, kontakt oss i Data Science avdelingen på Bouvet.
Vi ønsker deg lykke til med prosjektet!
Vestland fylkeskommune
Utvikling av Power BI-rapport for innkjøpsseksjonen i Vestland fylkeskommune

Bybanen
Smart prediksjon av isdannelse gir tryggere drift av Bybanen i Bergen

Arkivverket
Kunstig intelligens for ekstrahering av metadata fra dokumenter

Statens Vegvesen
Takting: Smart flåtestyring gjennom flaskehalser i veinettet

Agder Energi Nett
Skalerbar stordataplattform gir store innovasjonsmuligheter

eSmart