Hva er Natural Language Prosessing (NLP)?
Visste du at det er nesten 7000 språk i verden, og at cirka hver 14 dag blir et språk borte? Men visste du at en datamaskin ikke snakker noen av disse språkene - den forstår kun det binære alfabetet bestående av 0 og 1! Hvordan kan derfor en maskin forstå tekst?

Hva forstår datamaskinen?

Datamaskiner prosesserer informasjon ved hjelp av det binære alfabetet representert ved symbolene 0 og 1 som vi kaller bits. For at en datamaskin skal forstå det menneskers alfabetet og våres (arabiske) tall må vi oversette disse til en binær form. Vi bruker setningen under som eksempel:
Hva er klokka?
Det finnes flere måter å representere bokstavene og mellomrommet på binær form, men den vanligste vil være på kodeformen ASCII (American Standard Code for Information Interchange):
01001000 01110110 01100001 00100000 01100101 01110010 00100000 01101011 01101100 01101111 01101011 01101011 01100001 00111111
ASCII tolker den binære dataen i 8 bits samlinger og forbinder de til bokstaver og tegn. For å se mønsteret på ASCII form uttrykker vi det enklere med desimal formen av bokstavene:
| 072 | 118 | 097 | 032 | 101 | 114 | 032 |
H |
V |
A |
E |
R |
||
| 107 | 108 | 111 | 107 | 107 | 097 | 063 |
K |
L |
O |
K |
K |
A |
? |
For datamaskinen vil dette derfor fremstå som et sett med tall som den kan prosessere ved å behandle og manipulere tallene. Men vi har ennå ikke fortalt maskinen hvordan han skal behandle tallene!
Om vi for eksempel velger å legge sammen og deretter trekke fra en og en av ASCII verdien i rekkefølgen de står i får vi nytt et tall som representerer et ASCII-tegn.
Hva er klokka? = 72 + 118 – 97 +
32 – 101 + 114 – 32 + 107– 108 + 111 – 107 +
107 – 97 + 63 = 182 = ¶
Dette eksemplet illustrerer at det å legge sammen og trekke fra tallverdien til bokstavene gir ingen direkte mening. Vi må fortelle datamaskinen om hvordan har skal tolke og jobbe med teksten og det er her NLP kommer inn i bildet.
Hvor skal en datamaskin begynne?
Natural Language Processing (NLP) eller språkbehandling på godt norsk er et underfelt av lingvistikk, datavitenskap og maskinlæring som har som mål å forstå, analysere, manipulere og potensielt generere menneskelig språk. Mer konkret består feltet av et sett med algoritmer eller oppskrifter som gjenkjenner mønstre, strukturer og gjør logiske operasjoner på tekst. Disse algoritmene gjør det mulig for datamaskinen å bruke dem i modeller å for eksempel lese tekst, høre tale, tolke den, måle stemningen og bestemme hvilke deler av teksten som er viktige.
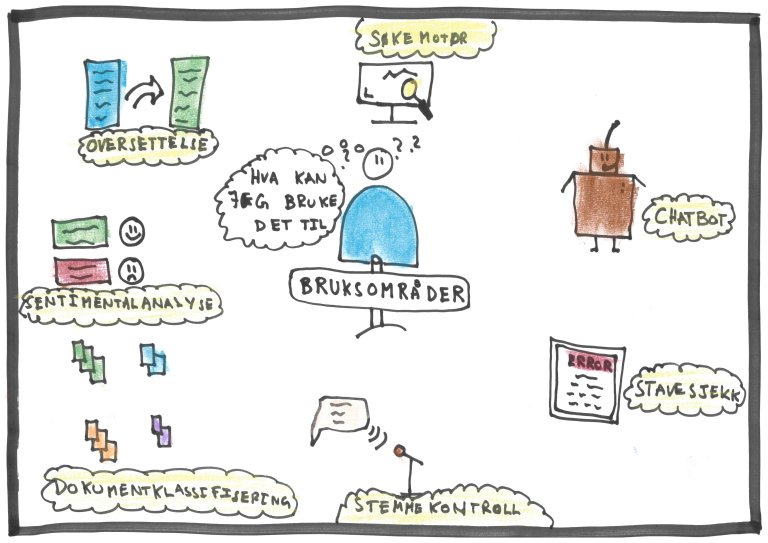
Enklere sagt henter NLP algoritmene ut informasjon fra menneskelig språk som kan brukes for å ta beslutninger. Denne informasjonen avhenger av den spesifikke oppgaven og bruksområdet som algoritmen skal løse. Typiske bruksområder vil være en chatbot, søkemotor, oversettelse mellom språk eller teknisk språk, dokumentklassifisering, stemmekontroll, stavesjekk og sentimentalanalyse (stemningsanalyse).
Under gir vi et eksempel på to tekster som vi ønsker å klassifisere i en av to grupper. Enten maskinlæring eller matoppskrift.
Tekst 1
Dette er en tekst som vi bruker for å illustrere hvordan en datamaskin prosessere naturlig (menneskelig) språk. Målet vil være å kategorisere teksten i en av to grupper, maskinlæring eller matoppskrifter.
Tekst 2
Dette er en tekst som inneholder en matoppskrift for boller. For å bake boller trenger man hvetemel, melk, smør, sukker, gjær, kardemomme og salt. Bland, kna ut deigen og la den heve en time. Stek bollene på 220 grader i 7 minutter.
For at vi skal få datamaskinen til å forstå teksten og kategorisere teksten riktig preprosesserer vi teksten til en form som er lettere for maskinen å jobbe med. Dette gjøres ved å dele preprosesseringen i deloppgaver.
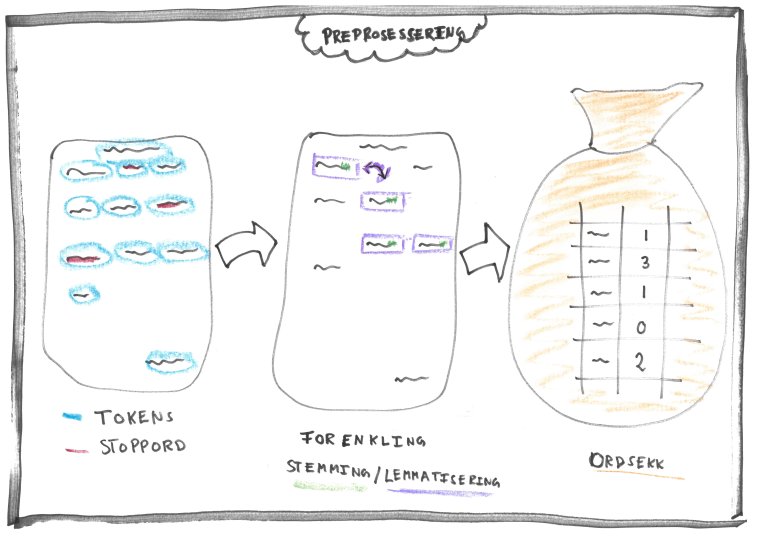
Tokens
Det første vi typisk gjør er å lære datamaskinen å organisere teksten i ord og setninger. Dette kalles på fagspråket for tokenization. Et "token" er det tekniske navnet på grunnenhet av enkeltstående eller en sekvens av karakterer (bokstaver og tegn). Resultatet av denne prosessen ser vi under.
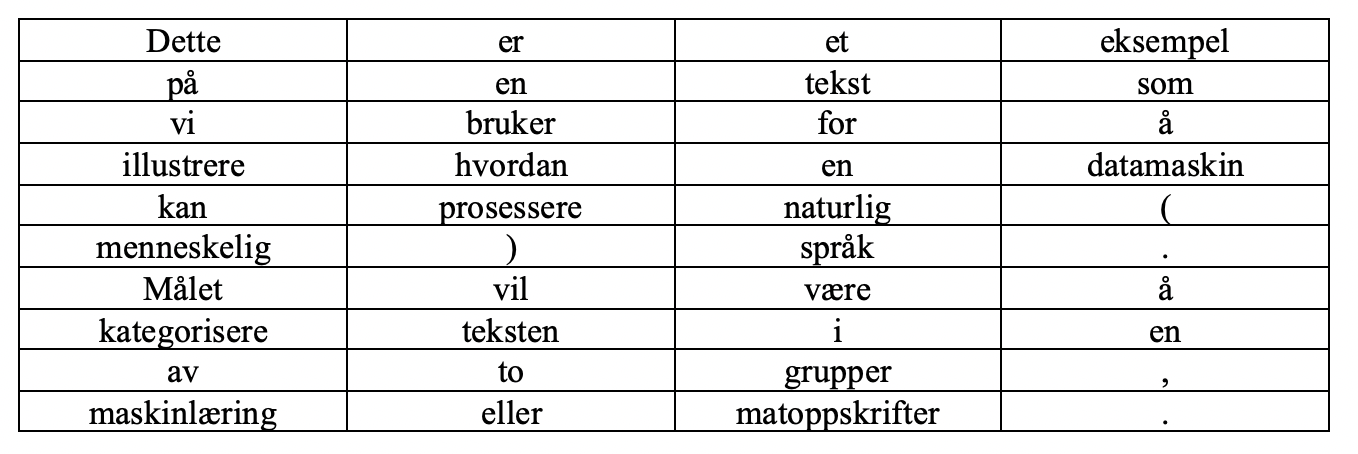
Merk at parentes, komma og punktum også vil være et token. Mellomrommet er også et token, men blir ofte ignorert ettersom den er der for lesbarheten ved å skille ordene fra hverandre. Fra vår liste med tokens finner vi alle grunnenhetene i dokumentet som kan ha betydning for klassifiseringen.
Stoppord
I mange tekster er det ord som dukker opp ofte, mens andre ord er mer uvanlige. Eksempler på ord som dukker opp ofte vil kunne være:
ikke, jeg, være, sånn, en, fordi
Om datamaskinen ønsker å forstå hva en tekst handler om vil disse ordene ikke være unike nok for teksten som analyseres. De dukker opp overalt og de finnes typisk i mange av tekstene våre. Vi ønsker derfor å fjerne disse ordene og sitte igjen med ord som vi kan bruke for å forstå innholdet. Ord som vi ønsker å filtrere vekk blir kalt for stoppord.
I vårt tilfelle ønsker vi å kategorisere teksten vår og ønsker derfor å fokusere på viktige ord i teksten som kan si noe om innholdet. Vi fjerner typiske stoppord, samt tegnene punktum, komma og parenteser siden de ikke gir oss relevant informasjon om hva teksten handler om.

Om vi ikke hadde fjernet stoppordene i teksten hadde algortimene prøvd å finne en sammenheng mellom et tilfeldig stoppord og klassen vi ønsker å predikere. Siden det finnes mange stoppord vil typisk disse sammenhengene dominere den endelige modellen vår. Dette vil igjen føre til at vi vil klassifiserer teksten på et misvisende grunnlag og vil ikke kunne predikere korrekt klasse for tekstene.
Merking og trekke ut ord
Å vite hvilken ordklasse et ord tilhører (verb, substantiv, adjektiv osv.) eller hvilken form ordet har (ubestemt, infinitiv osv.) kan gi informasjon om hva som skjer i setningen og eventuelt med hva.
Jeg kaster ballen.
Jeg: Pronomen, første person, subjektsform – kaster: verb, presens ballen: substantiv - entall
Det vil derfor kunne være viktig å kunne merke ordene med ordklasser for å forstå hva som skjer i setningen. Dette brukes ofte som et verktøy i lemmatisering, som vi skriver om under, for å forenkle teksten.
Stemming og lemmatisering
Vi har redusert teksten vår til en samling av ord. Det er to ord som uttrykket den samme betydning, tekst og teksten. Vi ønsker derfor å forenkle formen på disse ordene slik at de kan tolkes på samme måte. Dette kalles stemming på fagspråket. Rent teknisk innebærer stemming å fjerne endelsene til ordene. En endelse den uselvstendige slutten av et ord.
Får, hverdagslig, selvstendighet
Det vi sitter igjen med er stammen eller hoveddelen av ordet
Lemmatisering er en mer avansert metode enn å bare kutte av endelsene på ordene. Målet er derimot det samme som ved stemming. Å redusere bøyningsformene for hvert ord til en felles base eller rot.
Under lemmatiseringen kombinerer vi ordklassen til ordet med et lexicon. Et lexicon er en ordbok som knytter ordets grunnstein, lemma, med selve ordet, setningsstrukturen, ordets ordklasse og bøyningsformer. Ved å lemmatisere får vi en renere form for tekst, uavhengig av bøyningsform, suffikser og ordklasse.

Hvordan skal en datamaskin finne svaret?
Istedenfor en samling av bokstaver og tegn som vi hadde i vårt første eksempel har vi transformert teksten til en kort samling med ord. Siden vi ønsker å kategorisere denne teksten i en av to grupper trenger vi å representere disse ordene på en måte som datamaskinen kan gjenkjenne et mønster for hver gruppering. Dette gjør vi med å omformatere teksten til en tabell. Under er et utdrag av denne tabellen.

Radene i tabellen vil gjengi vokabularet eller ordforrådet vårt. Kolonnene i matrisen vil representere hver enkelt tekst. Tabellen beskriver forekomsten av hvert ord i hvert dokument og blir omtalt som en ordsekk.
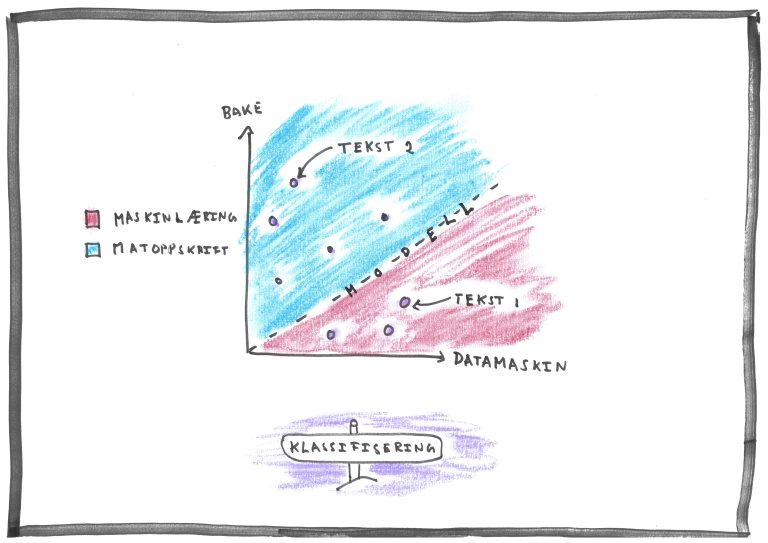
Vi ser tydelig fra tabellen at ord som bake og datamaskin er unike for hver av våre kategorier. Disse ordene vil derfor være kjennetegn til hver av våre to kategorier.
Veien videre
Ved å preprosessere, telle og finne strukturer har vi funnet kjennetegn som gjør at vi kan kategorisere tekstene i to forskjellige kategorier. Disse kjennetegnene vil være grunnlaget for en modell. I praksis er det ikke alltid like enkelt. Det finnes kanskje tusenvis av ord som går igjen i begge dokumentene og det vil være vanskelig å skille de fra hverandre på en god måte.
Tekstene kan derimot representeres på flere måter, som vektorer eller større tabeller fra nevrale nettverk. Målet er fortsatt det samme. Finne en god måte å representere teksten for datamaskinen slik at den effektiv og raskt kan finne mønstre og strukturer som kan svare på spørsmålet man ønsker svar på.
Dette er noe Data Science teamet i Bouvet har jobbet med i flere prosjekter. Vi har blant annet utviklet et flytskjema for å sjekke kvaliteten til et NLP-prosjekt.
Ta gjerne kontakt om du ønsker å vite mer om vårt arbeid eller har noen spørsmål om NLP!
Vestland fylkeskommune
Utvikling av Power BI-rapport for innkjøpsseksjonen i Vestland fylkeskommune

Bybanen
Smart prediksjon av isdannelse gir tryggere drift av Bybanen i Bergen

Elvia
Bildeanalyse og maskinlæring for mer effektive arbeidsprosesser

Arkivverket
Kunstig intelligens for ekstrahering av metadata fra dokumenter

Statens Vegvesen
Takting: Smart flåtestyring gjennom flaskehalser i veinettet

Agder Energi Nett