An Introduction to Deep Learning
Curious about Deep Learning? Read on for a mathematics and jargon free crash course in Deep Learning and Artificial Neural Networks!

What is Deep Learning?
Deep Learning is a a type of Machine Learning built upon multi-layered Artificial Neural Networks:
- Machine Learning allows computers to learn, make predictions and describe data without being explicitly programmed.
- Artificial Neural Networks (ANNs) are inspired by the neurons of the human brain. ANNs consist of a set of interconnected nodes that work together to perform complex statistical operations on incoming data.
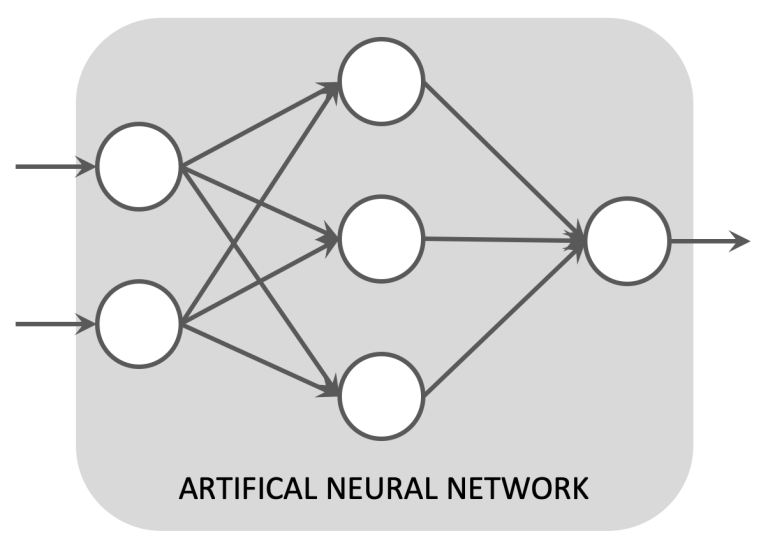
Before we delve into Deep Learning we must first understand Artificial Neural Networks.
The Anatomy of an Artificial Neural Network
A common starting point for understanding ANNs is the Feed Forward architecture. In this section we'll look at a typical Feed Forward ANN and explain the process of training it.
Layers in a Feed Forward ANN
Feed Forward ANNs organise their nodes into three distinct layers, with output from each layer being fed in to the next. Information flows in one direction, hence the Feed Forward name.
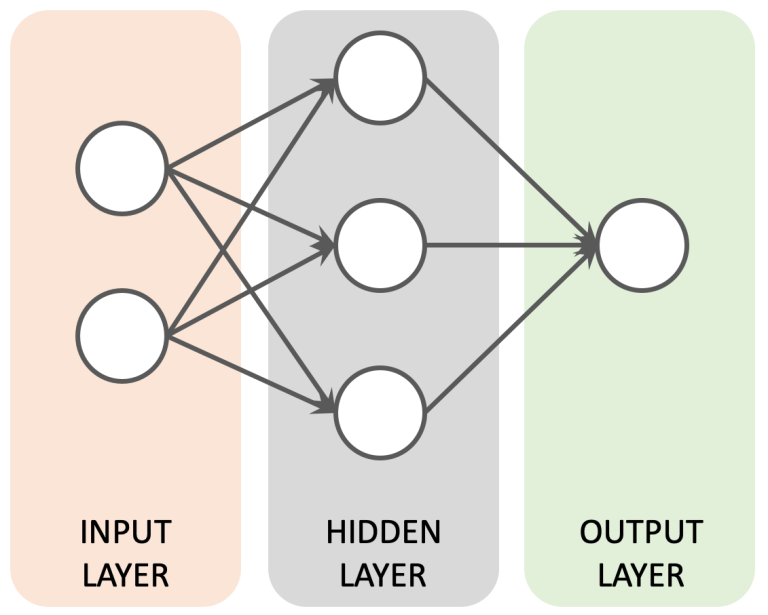
- Input Layer: The Input Layer provides an entry point for incoming data. As such it needs to match the format or "shape" of the expected input. For example, an RGB image 28 pixels high and 28 pixels wide might require an Input Layer of 2352 nodes organised into a 3D structure (28 x 28 x 3). In such a structure each node would represent the Red, Green or Blue value for a given pixel.
- Hidden Layer: Hidden layers are so called because they sit between the Input and Output Layers and have no contact with the "outside world". Their role is to identify features from the input data and use these to correlate between a given input and the correct output. An ANN can have multiple Hidden Layers.
- Output Layer: The Output Layer delivers the end result from the ANN and is structured according to the use case you are working on. For example, if you wanted an ANN to recognise 10 different objects in images you might want 10 output nodes, each representing one of the objects you are trying to find. The final score from each output node would then indicate whether or not the associated object had been found by the ANN.
Nodes in an Artificial Neural Network
As already mentioned, nodes in the Input Layer exist merely as an entry point for incoming data and perform no additional processing.
Nodes in the Hidden and Output Layers are more complex.
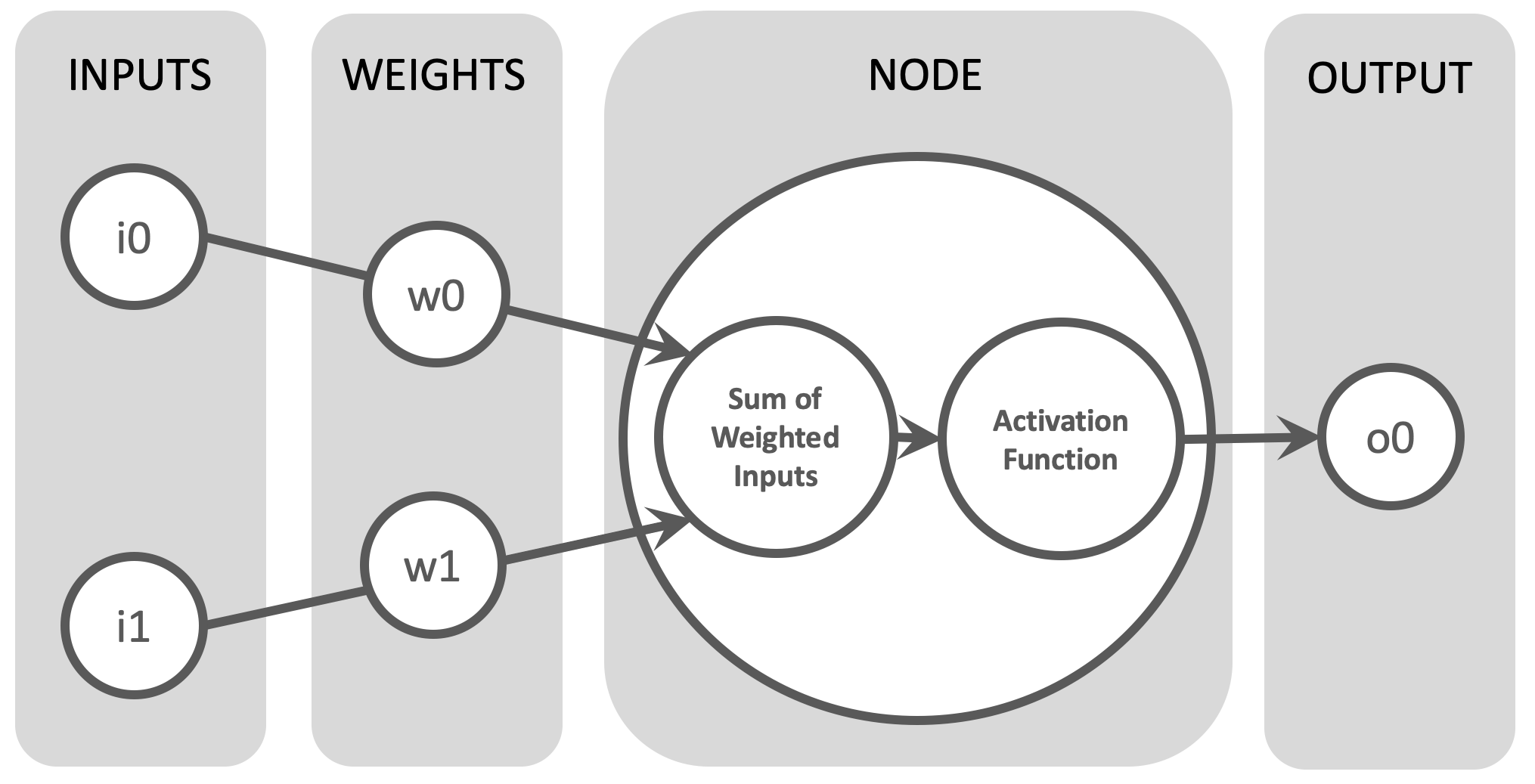
Nodes in the Hidden and Output Layers function as follows:
- Inputs: In the diagram above our node is recieving two seperate inputs (i0 and i1) from upstream nodes in the network. In reality a node will likely have much more than 2 parallel inputs.
- Weights: Each incoming connection has a weight (w0 and w1) applied to it's incoming value. Weights can positive or negative, having the effect of either amplifying or dampening the effect of the incoming input. Tuning these weights are an important part of the training process (which is discussed in the next section).
- Sum of weighted inputs: All weighted inputs to our node are added up into a single value.
- Activation Function: The main goal of the activation function is to convert the sum of weighted inputs into an output signal that is then sent further in the network. There are many different types of activation function, all with their own benefits and drawbacks.
- Output: The output (o0) is the result of the activation function. A non-null output generally means that the node has been activated or "triggered".
The pattern of activated nodes in an ANN is basically the ANNs internal mapping from the input to the output.
To see some examples of the internal activation of an ANN you can check out Adam Harley's visualisation of an ANN trained on the The MNIST database of handwritten digits. This a 4 layer ANN with the input layer at the bottom, two hidden layers and finally an output layer at the top. The visualisation is interactive so feel free to click on the nodes and play around with it.

The next question we need to answer is - how does the ANN learn these internal representations?
Training an Artificial Neural Network with Supervised Learning
Supervised Learning is a Machine Learning paradigm where we "help" our ANN to find the correlation between and input and output by training it with example input:output pairs.
This is pretty much the same as how we teach children the alphabet. We point at a letter and at the same time say what it is. Over time the children learn to associate the visual input with the desired response/output.
The process of training an ANN can be broken down into three steps:

Lets look at each of these steps in more detail:
Step 1: Generate Prediction (forward-propagation)
This is also known as forward-propagation.
Step 2: Calculating Loss
Loss or cost is a value representing the difference between an ANNs predictions and the desired output. A higher value indicates a larger gap between prediction and desired output.
ANNs use Loss Functions to calculate this value. Loss Functions come in many forms which in turn support different use cases. They are sometimes referred to as Cost Functions.
Step 3: Update Weights (back-propagation)
The weights in a ANN provide a mechanism for optimising the network and therefore reducing the Loss Function. This mechanism is known as back-propagation, as it's moves backwards through the ANN, updating weights as it goes.
We use an Optimiser Function to find out how best to adjust the ANN's weights to reduce the value of the Loss Function. Optimiser Functions come in different forms, but the most common ones are all based on some variation of Gradient Descent:
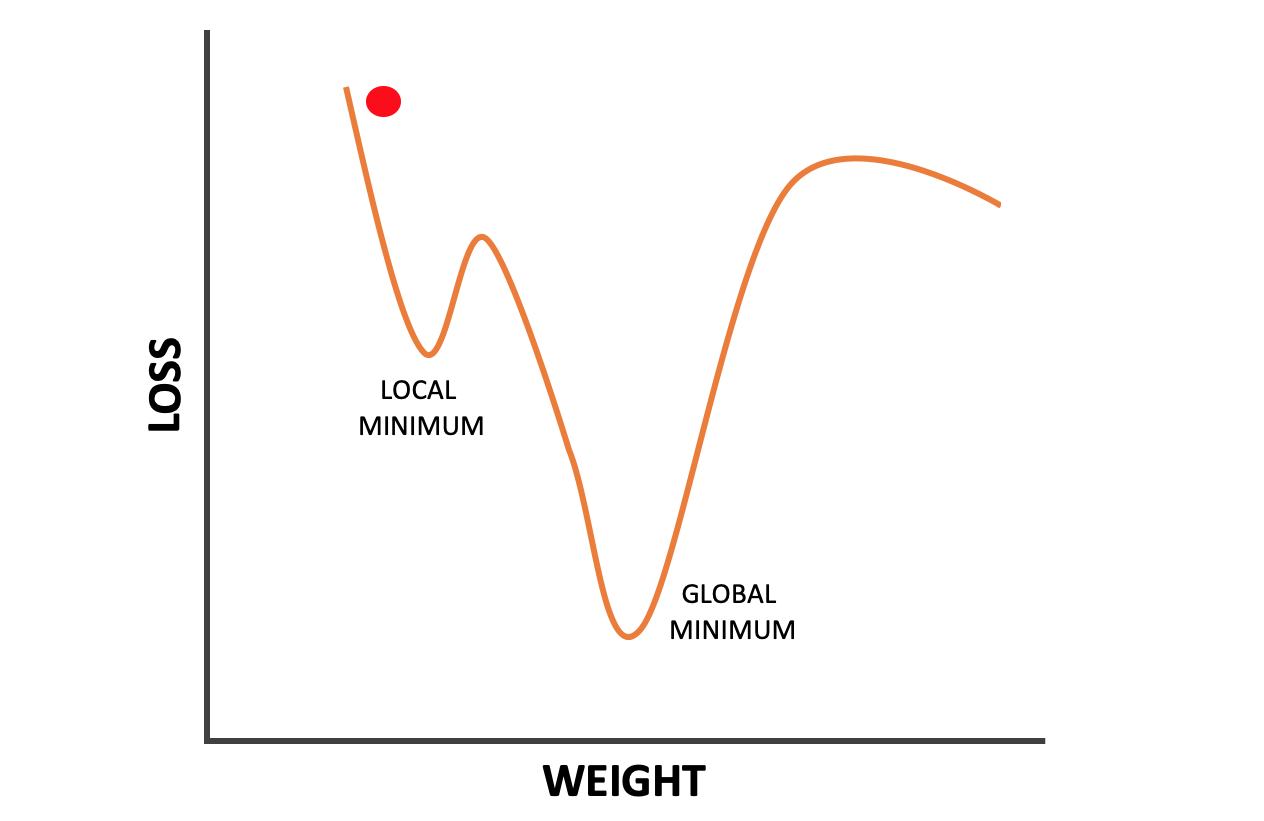
In essence the goal of Gradient Descent is to move the red ball down to the lowest point of the curve, or the Global Minimum. This represents the weight values that will give the lowest loss.
During training the ball will be moved "downhill" via incremental adjustments to weight values. The size of these adjustments are known as the Learning Rate. A large Learning Rate can cause the ball to take bigger steps, and perhaps hop over the Global Minimum, while a small Learning Rate will result in ANNs that take very small steps and are very slow to train.
An extra challenge here is that our Optimiser Function has no overview of the gradient that is going to descend. All it knows is that it wants to move downhill. A common problem for Optimiser Functions is therefore that they get stuck in a Local Minimum or on a plateau.
By working backwards through the ANN and adjusting it's weights, back-propagation helps the ANN to optimise it's behaviour over multiple training rounds.
Deep Learning in Artificial Neural Networks
A common definition of Deep Learning is "ANNs with more than one Hidden Layer". In other words, the more Hidden Layers an ANN has, the "deeper" it can be said to be.
The role of the Hidden Layers is to identify features from the input data and use these to correlate between a given input and the correct output.
Deep Learning allows ANNs to handle complex feature hierarchies by supporting a step by step process of pattern recognition, where each Hidden Layer builds upon the "knowledge" from previous ones.
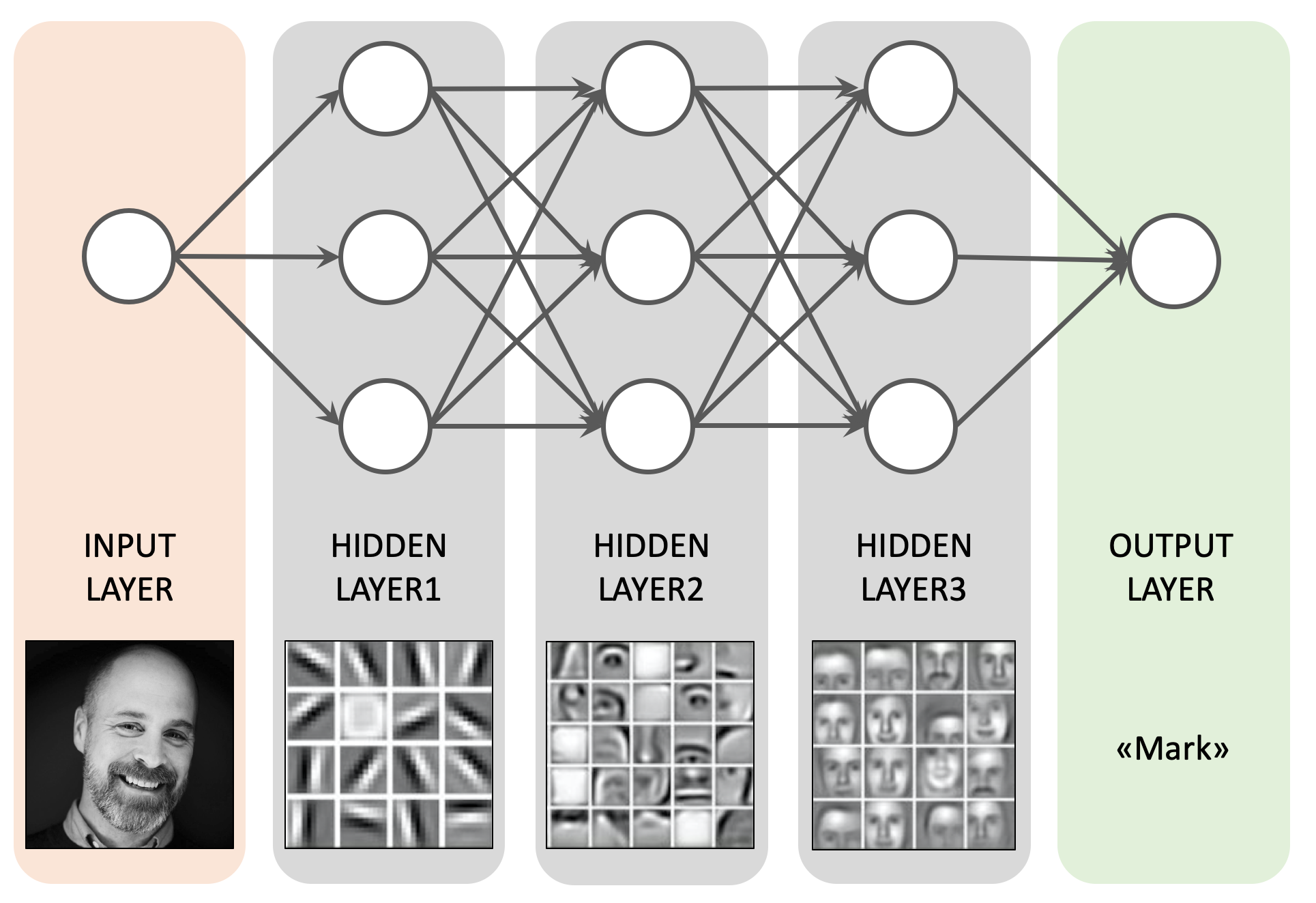
In the above facial recognition example we have three Hidden Layers. Each of these aggregates and recombines features from the previous layer.
A drawback of Deep Learning is that the feature representations in Hidden Layers are not always human readable like the above example. This means that it can be extremely difficult to get insight into what a Deep Learning ANN delivers a specific result, especially if ANN is working in more than 3 dimensions.
Types of Deep Learning Architectures
Many Deep Learning Architectures exist. These are all based on ANNs, but have specific optimatisations that make them good for certain use cases. Some examples:
- Multi Layer Perception (MLPs): MLPs are a type of Feed Forward ANN where all nodes are in a given layer are connected to all the nodes in the next layer, and so on. They are perfom well for classification and regression, but the sheer amount of connections (and their accompanying weights) mean that MLPs demand a lot of processing power for relatively simple tasks.
- Convolutional Neural Networks (CNNs): The most popular solution for Image Processing due to their ability to handle spatial data, CNNs also have a more efficient structure and require less processing power than MLPs.
- Recurrent Neural Networks (RNNs): These are built for sequential data and are therefore popular for Natural Language Processing.
- Hybrid Models: Combining different type of ANNs can unlock complex use cases, such as combining CNN and RNN to process a sequence of images or frames in a video stream.
Transfer Learning
One of the cool aspects of Deep Learning is the possibility of Transfer Learning. Transfer Learning is where you copy a previously trained Deep Learning model and retrain it for another task. This can be a shortcut to getting a new model quickly up and running, or for dealing with use cases with small amounts of training data.
For Transfer Learning to succeed the new use case needs to share learned features with the new use case. You won't be able to retrain a facial recognition model to perfom text classification, for example, but you might be able to use it for other Image Processing tasks.
Questions to ask before using Deep Learning
Deep Learning has many potential applications, including Computer Vision, Natural Language Processing, Pattern Recognition. Process Optimisation, Feature Extraction and much more.
Here are some questions that provide a quick sanity check before choosing to apply Deep Learning to your next project.
Q: Do you have good knowledge of Mathematics and Applied Statistics?
This knowledge will be necessary to help you configure your Deep Learning ANN, prepare your training data, interpret the output from your ANN as well as helping you deal with unexpected results.
Q: Have you ruled out simpler Machine Learning methods?
Deep Learning is merely one tool in the Machine Learning toolbox. It is also one of the most complex and time consuming. Instead of going straight for Deep Learning, use some time to look into simpler alternatives.
Q: Do you have plenty of varied training data available?
Deep Learning projects generally perform better when they have access to large amounts of varied data. This gives Hidden Layers enough information perform automatic feature extraction. Lack of variation in your training data can give rise to biased models.
Q: Do you need insight to why your Deep Learning ANN made a specific decision?
One of the weaknesses of Deep Learning is the lack of Interpretability. Deep Learning ANNs build their own feature hierarchies from the training data, based upon mathematical operations. These feature hierarchies may not be easily interpretable by humans. This can be a problem if you have to explain to a customer why your ANN rejected their application for a credit extension.
Q: Do you have the necessary processing power and data storage available?
Deep Learning can be resource intensive. Not only do you need processing power for training the model, but you also need data storage for all your training data. In the era of cloud computing these problems are easily solvable, but can potentially lead to big costs.
Q: Is there a lack of domain understanding for feature extraction?
If the answer is "yes" then Deep Learning might be able to help you with this! Deep Learning ANNs perform automatic feature extraction without human intervention. This makes them very suitable for cases where manual feature identification is not possible.
Q: How will you deploy your Deep Learning ANN to production?
How will you deal with problems such as Data Drift? Do you need to retrain your ANN often? How will you monitor it's performance? Do you have a data pipeline ready? Many people forget to address these questions until it is too late.
Q: How will you evaluate your Deep Learning ANN?
When is your model good enough? 98% accuracy? 65%? What is your businesses acceptable margin of error?
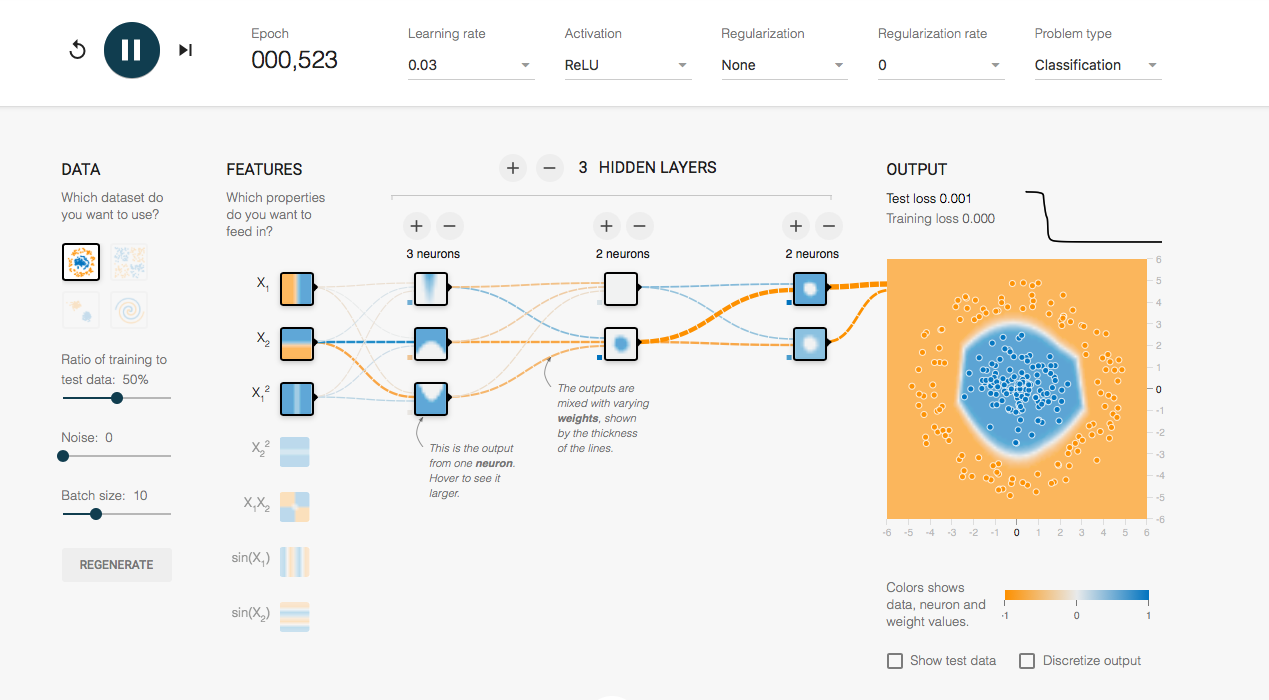
Play with an Artificial Neural Network in your Browser!
A Neural Network Playground is a browser based application that allows you to configure and run an Artificial Neural Network (with 0 to 6 Hidden Layers) to solve simple classification problems.
Vestland fylkeskommune
Utvikling av Power BI-rapport for innkjøpsseksjonen i Vestland fylkeskommune

Bybanen
Smart prediksjon av isdannelse gir tryggere drift av Bybanen i Bergen

Elvia
Bildeanalyse og maskinlæring for mer effektive arbeidsprosesser

Arkivverket
Kunstig intelligens for ekstrahering av metadata fra dokumenter

Statens Vegvesen
Takting: Smart flåtestyring gjennom flaskehalser i veinettet

Agder Energi Nett